
DP-203 試験問題 176
Azure Synapse Analytics サーバーレス SQL プール、Azure Synapse Analytics 専用 SQL プール、Apache Spark プール、および Azure Data Lake Storage Gen2 アカウントがある。
Lake データベースにテーブルを作成する必要があります。テーブルはサーバーレス SQL プールと Spark プールの両方で使用できる必要があります。
テーブルをどこに作成する必要がありますか?また、テーブル内のデータにはどのファイル形式を使用する必要がありますか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。

Lake データベースにテーブルを作成する必要があります。テーブルはサーバーレス SQL プールと Spark プールの両方で使用できる必要があります。
テーブルをどこに作成する必要がありますか?また、テーブル内のデータにはどのファイル形式を使用する必要がありますか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。

DP-203 試験問題 177
SQLPool1 という名前の Azure Synapse Analytics 専用 SQL プールを含む Azure サブスクリプションがあります。
SQLPool1 は現在一時停止されています。
SQLPool1 の現在の状態を新しい SQL プールに復元する必要があります。
まず何をすべきでしょうか?
SQLPool1 は現在一時停止されています。
SQLPool1 の現在の状態を新しい SQL プールに復元する必要があります。
まず何をすべきでしょうか?
DP-203 試験問題 178
Table1 という名前のテーブルを含む Azure Synapse Analytics 専用 SQL プールがあります。
取り込まれ、container1 という名前の Azure Data Lake Storage Gen2 コンテナーに読み込まれるファイルがあります。
ファイルからのデータを Table1 と、container1 という名前の Azure Data Lake Storage Gen2 コンテナーに挿入する予定です。
ファイルのデータを Table1 に挿入し、データを変換することを計画しています。ファイル内のデータの各行は、Table1 のサービス層に 1 行を生成します。
ソース データ ファイルがcontainer1にロードされるときに、DateTimeがTable1の追加列として格納されることを確認する必要があります。
解決策: Azure Synapse Analytics パイプラインでは、派生列変換を含むデータ フローを使用します。
取り込まれ、container1 という名前の Azure Data Lake Storage Gen2 コンテナーに読み込まれるファイルがあります。
ファイルからのデータを Table1 と、container1 という名前の Azure Data Lake Storage Gen2 コンテナーに挿入する予定です。
ファイルのデータを Table1 に挿入し、データを変換することを計画しています。ファイル内のデータの各行は、Table1 のサービス層に 1 行を生成します。
ソース データ ファイルがcontainer1にロードされるときに、DateTimeがTable1の追加列として格納されることを確認する必要があります。
解決策: Azure Synapse Analytics パイプラインでは、派生列変換を含むデータ フローを使用します。
DP-203 試験問題 179
Azure Synapse Analytics 専用 SQL プールの製品カテゴリ データに対してタイプ 3 のゆっくりと変化するディメンション (SCD) を実装する必要があります。
次の Transact-SQL ステートメントを使用して作成されたテーブルがあります。
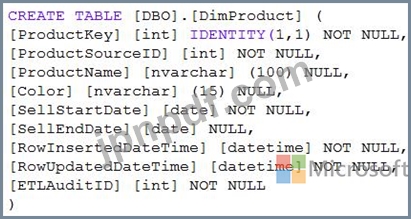
どの 2 つの列をテーブルに追加する必要がありますか? それぞれの正解は、解決策の一部を示しています。
注: 正しく選択するたびに 1 ポイントの価値があります。
次の Transact-SQL ステートメントを使用して作成されたテーブルがあります。
どの 2 つの列をテーブルに追加する必要がありますか? それぞれの正解は、解決策の一部を示しています。
注: 正しく選択するたびに 1 ポイントの価値があります。
DP-203 試験問題 180
Azure Synapse Analytics 専用 SQL プールにテーブルをバッチ読み込みしています。
ステージング テーブルからターゲット テーブルにデータをロードする必要があります。ソリューションでは、ターゲット テーブルへのデータのロード中にエラーが発生した場合、そのバッチ内のすべての挿入が確実に元に戻されるようにする必要があります。
Transact-SQL コードをどのように完成させるべきでしょうか? 答えるには、適切な値を正しいターゲットにドラッグします。各値は 1 回使用することも、複数回使用することも、まったく使用しないこともできます。コンテンツを表示するには、ペイン間で分割バーをドラッグするか、スクロールする必要がある場合があります。
注意 正しい選択はそれぞれ 1 ポイントの価値があります。
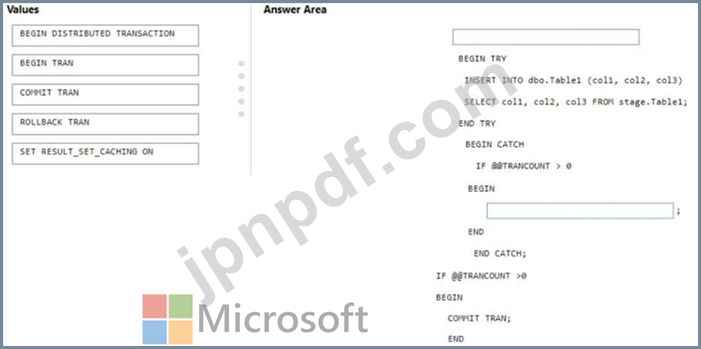
ステージング テーブルからターゲット テーブルにデータをロードする必要があります。ソリューションでは、ターゲット テーブルへのデータのロード中にエラーが発生した場合、そのバッチ内のすべての挿入が確実に元に戻されるようにする必要があります。
Transact-SQL コードをどのように完成させるべきでしょうか? 答えるには、適切な値を正しいターゲットにドラッグします。各値は 1 回使用することも、複数回使用することも、まったく使用しないこともできます。コンテンツを表示するには、ペイン間で分割バーをドラッグするか、スクロールする必要がある場合があります。
注意 正しい選択はそれぞれ 1 ポイントの価値があります。
