
DP-100 試験問題 146
注: この質問は、同じシナリオを示す一連の質問の一部です。このシリーズの各質問には、指定された目標を達成できる可能性のある独自の解決策が含まれています。一部の質問セットには複数の正しい解決策が含まれる場合がありますが、他の質問セットには正しい解決策がない場合があります。
このセクションの質問に回答すると、その質問に戻ることはできません。そのため、これらの質問はレビュー画面には表示されません。
あなたは、Azure Machine Learning Studio を使用するデータ サイエンティストです。
ターゲット列を予測するには、値を正規化して出力列をビンに生成する必要があります。
解決策: QuantileIndex 正規化を使用して Quantiles 正規化を適用します。
解決策は目標を達成していますか?
このセクションの質問に回答すると、その質問に戻ることはできません。そのため、これらの質問はレビュー画面には表示されません。
あなたは、Azure Machine Learning Studio を使用するデータ サイエンティストです。
ターゲット列を予測するには、値を正規化して出力列をビンに生成する必要があります。
解決策: QuantileIndex 正規化を使用して Quantiles 正規化を適用します。
解決策は目標を達成していますか?
DP-100 試験問題 147
次のように定義された 6 つのデータ ポイントを含む Python NumPy 配列を評価しています。
データ = [10、20、30、40、50、60]
Python Scikit-learn 機械学習ライブラリの k-fold アルゴリズム注入を使用して、次の出力を生成する必要があります。
トレイン: [10 40 50 60]、テスト: [20 30]
トレイン: [20 30 40 60]、テスト: [10 50]
トレイン: [10 20 30 50]、テスト: [40 60]
出力を生成するには、相互検証を実装する必要があります。
コードセグメントをどのように完成させるべきでしょうか? 回答するには、回答領域のダイアログ ボックスで適切なコード セグメントを選択します。
注: 正しく選択するたびに 1 ポイントの価値があります。

データ = [10、20、30、40、50、60]
Python Scikit-learn 機械学習ライブラリの k-fold アルゴリズム注入を使用して、次の出力を生成する必要があります。
トレイン: [10 40 50 60]、テスト: [20 30]
トレイン: [20 30 40 60]、テスト: [10 50]
トレイン: [10 20 30 50]、テスト: [40 60]
出力を生成するには、相互検証を実装する必要があります。
コードセグメントをどのように完成させるべきでしょうか? 回答するには、回答領域のダイアログ ボックスで適切なコード セグメントを選択します。
注: 正しく選択するたびに 1 ポイントの価値があります。


DP-100 試験問題 148
次の形式の salesData という名前の Python データ フレームがあります。

データ フレームは、次のように長いデータ形式にアンピボットする必要があります。
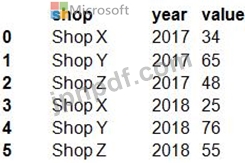
変換を実行するには、Python の pandas.melt() 関数を使用する必要があります。
コードセグメントをどのように完成させるべきでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。

データ フレームは、次のように長いデータ形式にアンピボットする必要があります。
変換を実行するには、Python の pandas.melt() 関数を使用する必要があります。
コードセグメントをどのように完成させるべきでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。

DP-100 試験問題 149
Azure ML SDK を使用して実験を実行する準備をしており、コンピューティングを作成する必要があります。次のコードを実行します。

次の各ステートメントについて、そのステートメントが true の場合は [はい] を選択します。それ以外の場合は、「いいえ」を選択します。
注: 正しく選択するたびに 1 ポイントの価値があります。

次の各ステートメントについて、そのステートメントが true の場合は [はい] を選択します。それ以外の場合は、「いいえ」を選択します。
注: 正しく選択するたびに 1 ポイントの価値があります。


DP-100 試験問題 150
生物医学研究会社は、実験的な治療試験に人々を登録することを計画しています。
二項分類モデルを作成してトレーニングし、患者の選択と治験への参加をサポートします。モデルには、年齢、性別、民族の特徴が含まれています。
このモデルは、異なる民族グループの人々に対して異なるパフォーマンス指標を返します。
民族性機能の各カテゴリの格差を軽減し、最小限に抑えるには、Fairlearn を使用する必要があります。
どのテクニックと制約を使用する必要がありますか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。

二項分類モデルを作成してトレーニングし、患者の選択と治験への参加をサポートします。モデルには、年齢、性別、民族の特徴が含まれています。
このモデルは、異なる民族グループの人々に対して異なるパフォーマンス指標を返します。
民族性機能の各カテゴリの格差を軽減し、最小限に抑えるには、Fairlearn を使用する必要があります。
どのテクニックと制約を使用する必要がありますか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。
