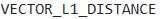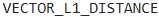GES-C01 試験問題 31
開発チームは、Snowflake Cortex LLM関数を用いて、特に会話型タスクとテキスト生成タスク向けのGen AIアプリケーションを構築しています。トークン消費による潜在的なコスト高を懸念しています。これらのCortex LLM関数を使用する際に、トークン使用量を最小限に抑え、コストを最適化するのに最も効果的な戦略はどれでしょうか?
GES-C01 試験問題 32
データアナリストは顧客からのフィードバックテキストを含むテーブルを扱っており、Snowflake内で様々なテキスト分析タスクを効率的に実行する必要があります。レビューを要約し、感情を判断し、特定の情報を抽出したいと考えています。以下のSnowflake Cortex LLM関数のうち、テキスト列に適用した場合、目的の結果を達成し、指定された出力タイプを返すものはどれですか?
GES-C01 試験問題 33
ある多国籍企業が複数のAWSリージョンでSnowflakeを使用しています。主要な運用SnowflakeアカウントはAWS米国東部(オハイオ)にありますが、特定のAI_COMPLETEモデル(llama4-maverick)を活用する必要があります。このモデルはAWS米国東部1(バージニア北部)ではネイティブで利用可能ですが、米国東部(オハイオ)では利用できません。この問題を解決するため、Snowflake管理者は米国東部(オハイオ)アカウントでクロスリージョン推論を有効にしました。
GES-C01 試験問題 34
データプラットフォームアーキテクトは、新しい検索アプリケーション用の複雑なデータパイプラインに「SNOWFLAKE.CORTEX.EMBED TEXT 768」を統合しようとしています。このパイプラインでは、様々なソースからテキストを抽出し、埋め込みを生成してSnowflakeに保存し、セマンティック検索を実行します。Snowflake内で「EMBED TEXT 768」とその結果生成される「VECTOR」データ型を扱う際の互換性に関する側面または制限事項について、以下の記述のうちどれが正確に説明されていますか?
GES-C01 試験問題 35
機械学習エンジニアが、Snowflakeで商品レコメンデーションシステムを構築しています。このシステムは、類似度マッチングにアイテム埋め込みと顧客クエリ埋め込みを使用しています。VECTOR_L1_DISTANCE関数を使用して、ユーザーのクエリに最も近い商品を検索する予定です。このアプローチにおけるコストとデータ型の考慮事項について、最も適切に説明されている記述はどれですか?