
GES-C01 試験問題 41
データアナリストは、長文の英語記事を格納する列(VARCHAR)を含むARTICLE_CONTENTというテーブルを操作しています。各記事について簡潔な要約を生成する必要があります。アナリストはSNOWFLAKE.CORTEX.SUMMARIZE関数を使用する予定です。単一記事要約の構文と結果の予想されるデータ型を正しく説明しているものは次のうちどれですか?
GES-C01 試験問題 42
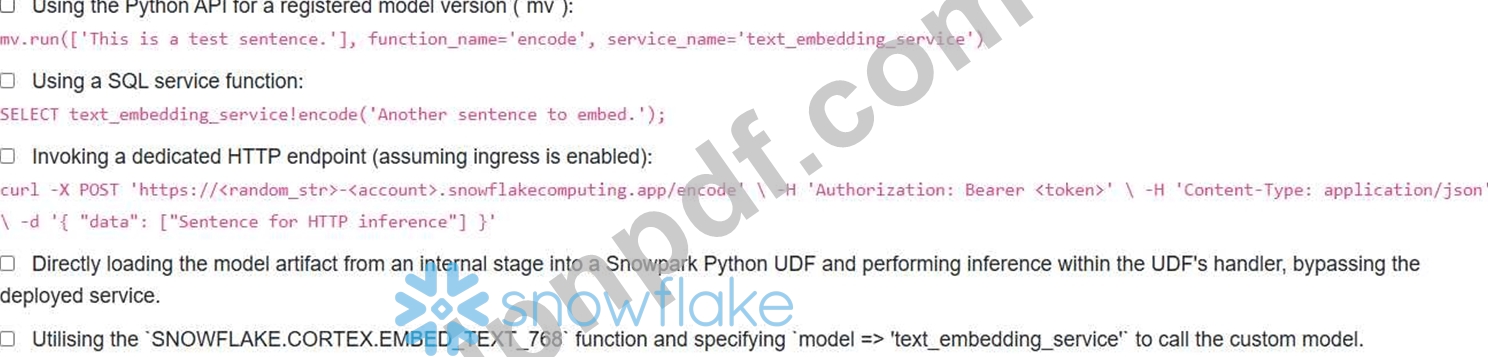
MLエンジニアは、Snowflakeアカウント内のSnowparkコンテナサービス「text embedding_service」に、カスタムテキスト埋め込みモデル「my_embedder model」を正常にデプロイしました。このモデルには、文字列を受け入れてベクトルを返す「encode」メソッドがあります。エンジニアは、このデプロイ済みモデルからの推論呼び出しを様々なアプリケーションに統合する必要があります。このモデルを推論のために呼び出す有効な方法は、次のうちどれですか?
GES-C01 試験問題 43
Streamlitアプリケーション開発者は、AI_COMPLETE(COMPLETE(SNOWFLAKE.CORTEX)の最新バージョン)を使用して顧客フィードバックを処理したいと考えています。目標は、顧客の感情、言及された製品、具体的な問題などの構造化された情報を、予測可能なJSON形式で抽出し、データベースに即座に取り込むことです。この構造化された出力要件を満たすには、AI_COMPLETE関数呼び出しのどの構成が不可欠ですか?

GES-C01 試験問題 44
開発者は、Cortex Fine-tuningパイプラインを自動化されたデータワークフローに統合しており、構造化された出力を確保し、プロセスを効果的に監視する必要があります。また、Snowflakeには特定のアーキテクチャ上の制限があることも認識しています。Snowflake Cortex Fine-tuningおよび関連するLLM機能の高度な使用方法や制限に関する以下の記述のうち、正しいものはどれですか?(該当するものをすべて選択してください)
GES-C01 試験問題 45
データエンジニアリングチームは、毎日数百万件ものドキュメントを処理するために「SNOWFLAKE.CORTEX.EMBED_TEXT 768」に大きく依存する検索拡張生成(RAG)パイプラインを構築しています。コストと検索品質の両方を最適化する必要があります。Snowflakeにおける「EMBED_TEXT 768」のコストとパフォーマンスに関して、正しい記述は次のうちどれですか?(該当するものをすべて選択してください)