DP-700 試験問題 11
ホットスポット
アドホック クエリの問題をトラブルシューティングする必要があります。
この文をどのように完成させるべきでしょうか? 回答するには、回答エリアで適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが加算されます。

アドホック クエリの問題をトラブルシューティングする必要があります。
この文をどのように完成させるべきでしょうか? 回答するには、回答エリアで適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが加算されます。


DP-700 試験問題 12
Lakehouse1 という名前のレイクハウスを含む Fabric ワークスペースがあります。
外部データソースには、それぞれ500GBのデータファイルがあり、毎日新しいファイルが追加されます。
Lakehouse1 にデータを一切変換せずに取り込む必要があります。ソリューションは以下の要件を満たす必要があります。新しいファイルが追加されたときにプロセスがトリガーされます。
最高のスループットを提供します。
データを取り込むにはどのタイプのアイテムを使用する必要がありますか?
外部データソースには、それぞれ500GBのデータファイルがあり、毎日新しいファイルが追加されます。
Lakehouse1 にデータを一切変換せずに取り込む必要があります。ソリューションは以下の要件を満たす必要があります。新しいファイルが追加されたときにプロセスがトリガーされます。
最高のスループットを提供します。
データを取り込むにはどのタイプのアイテムを使用する必要がありますか?
DP-700 試験問題 13
注: この質問は、同じシナリオを提示する一連の質問の一部です。一連の質問にはそれぞれ、定められた目標を満たす可能性のある独自の解答が含まれています。質問セットによっては、複数の正解が存在する場合もあれば、正解がない場合もあります。
このセクションの質問に回答した後は、その質問に戻ることはできません。そのため、これらの質問はレビュー画面に表示されません。
KQLデータベース内のBike_LocationというテーブルにデータをロードするFabricイベントストリームがあります。このテーブルには以下の列が含まれています。
バイクポイントID
通り
近所
自転車禁止
空のドックなし
タイムスタンプ
データを利用できるようにするには、変換とフィルターロジックを適用する必要があります。ソリューションは、No_Bikes が 15 以上の場合に、Sands End という地区のデータを返す必要があります。結果は No_Bikes の昇順で並べる必要があります。
解決策: 次のコード セグメントを使用します。

これは目標を満たしていますか?
このセクションの質問に回答した後は、その質問に戻ることはできません。そのため、これらの質問はレビュー画面に表示されません。
KQLデータベース内のBike_LocationというテーブルにデータをロードするFabricイベントストリームがあります。このテーブルには以下の列が含まれています。
バイクポイントID
通り
近所
自転車禁止
空のドックなし
タイムスタンプ
データを利用できるようにするには、変換とフィルターロジックを適用する必要があります。ソリューションは、No_Bikes が 15 以上の場合に、Sands End という地区のデータを返す必要があります。結果は No_Bikes の昇順で並べる必要があります。
解決策: 次のコード セグメントを使用します。
これは目標を満たしていますか?

DP-700 試験問題 14
注: この質問は、同じシナリオを提示する一連の質問の一部です。一連の質問にはそれぞれ、定められた目標を満たす可能性のある独自の解答が含まれています。質問セットによっては、複数の正解が存在する場合もあれば、正解がない場合もあります。
このセクションの質問に回答した後は、その質問に戻ることはできません。そのため、これらの質問はレビュー画面に表示されません。
StreamとReferenceという2つのテーブルを含むKQLデータベースがあります。Streamには、次の形式のストリーミングデータが含まれています。

参照には次の形式の参照データが含まれます。

どちらのテーブルにも数百万の行が含まれています。
次の KQL クエリセットがあります。

KQL クエリセットの実行にかかる時間を短縮する必要があります。
解決策: 出力列に make_list() 関数を追加します。
これは目標を満たしていますか?
このセクションの質問に回答した後は、その質問に戻ることはできません。そのため、これらの質問はレビュー画面に表示されません。
StreamとReferenceという2つのテーブルを含むKQLデータベースがあります。Streamには、次の形式のストリーミングデータが含まれています。
参照には次の形式の参照データが含まれます。
どちらのテーブルにも数百万の行が含まれています。
次の KQL クエリセットがあります。
KQL クエリセットの実行にかかる時間を短縮する必要があります。
解決策: 出力列に make_list() 関数を追加します。
これは目標を満たしていますか?
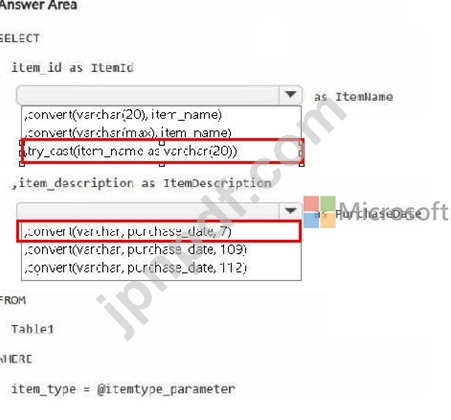
DP-700 試験問題 15
ホットスポット
Fabric ワークスペースがあります。
ステートメントをデバッグしているときに、次の問題が見つかりました。
場合によっては、ステートメントが予期されるすべての行を返さないことがあります。
PurchaseDate 出力列は、予期された mmm dd, yy の形式ではありません。
問題を解決する必要があります。解決策では、結果のデータ型が保持される必要があります。結果には空白のセルが含まれる場合があります。
この文をどのように完成させるべきでしょうか? 回答するには、回答エリアで適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが加算されます。

Fabric ワークスペースがあります。
ステートメントをデバッグしているときに、次の問題が見つかりました。
場合によっては、ステートメントが予期されるすべての行を返さないことがあります。
PurchaseDate 出力列は、予期された mmm dd, yy の形式ではありません。
問題を解決する必要があります。解決策では、結果のデータ型が保持される必要があります。結果には空白のセルが含まれる場合があります。
この文をどのように完成させるべきでしょうか? 回答するには、回答エリアで適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが加算されます。