
DP-700 試験問題 46
注: この質問は、同じシナリオを提示する一連の質問の一部です。一連の質問にはそれぞれ、定められた目標を満たす可能性のある独自の解答が含まれています。質問セットによっては、複数の正解が存在する場合もあれば、正解がない場合もあります。
このセクションの質問に回答した後は、その質問に戻ることはできません。そのため、これらの質問はレビュー画面に表示されません。
StreamとReferenceという2つのテーブルを含むKQLデータベースがあります。Streamには、次の形式のストリーミングデータが含まれています。

参照には次の形式の参照データが含まれます。

どちらのテーブルにも数百万の行が含まれています。
次の KQL クエリセットがあります。

KQL クエリセットの実行にかかる時間を短縮する必要があります。
解決策: プロジェクトを変更して拡張します。
これは目標を満たしていますか?
このセクションの質問に回答した後は、その質問に戻ることはできません。そのため、これらの質問はレビュー画面に表示されません。
StreamとReferenceという2つのテーブルを含むKQLデータベースがあります。Streamには、次の形式のストリーミングデータが含まれています。
参照には次の形式の参照データが含まれます。
どちらのテーブルにも数百万の行が含まれています。
次の KQL クエリセットがあります。
KQL クエリセットの実行にかかる時間を短縮する必要があります。
解決策: プロジェクトを変更して拡張します。
これは目標を満たしていますか?
DP-700 試験問題 47
あなたの会社には開発チームがあります。チームは、データ変換に使用する再利用可能なコードのPythonライブラリを作成しています。
ノートブックを使用して抽出、変換、ロード (ETL) ソリューションを開発するために使用する Fabric ワークスペース名 Workspace1 を作成します。
Workspace1 の新しいノートブックでライブラリがデフォルトで使用できることを確認する必要があります。
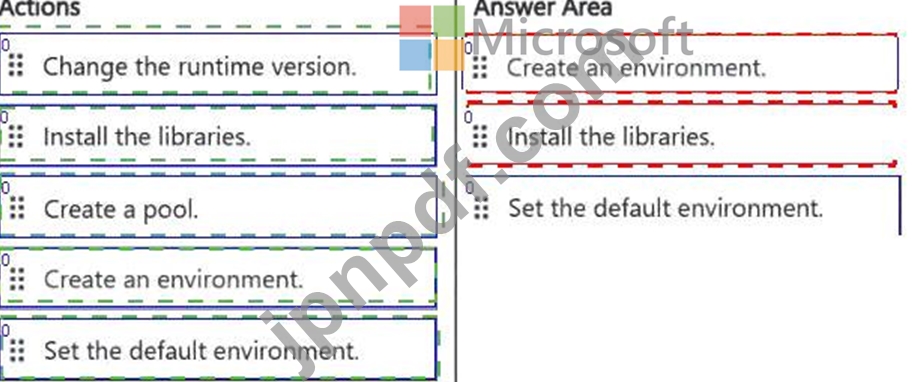
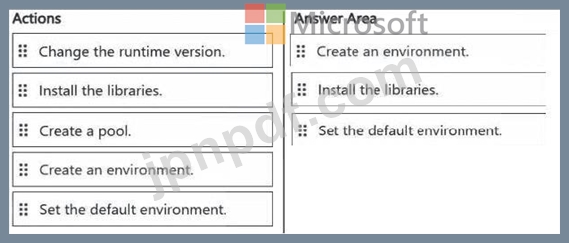
順番に実行する必要がある 3 つのアクションはどれですか。回答するには、適切なアクションをアクション リストから回答領域に移動し、正しい順序に並べます。

ノートブックを使用して抽出、変換、ロード (ETL) ソリューションを開発するために使用する Fabric ワークスペース名 Workspace1 を作成します。
Workspace1 の新しいノートブックでライブラリがデフォルトで使用できることを確認する必要があります。
順番に実行する必要がある 3 つのアクションはどれですか。回答するには、適切なアクションをアクション リストから回答領域に移動し、正しい順序に並べます。
DP-700 試験問題 48
WorkspaceA がソース管理用に構成できることを確認する必要があります。実行すべき 2 つのアクションはどれですか。
それぞれの正解は解決策の一部を示しています。注: 正解の選択ごとに1ポイントが加算されます。
それぞれの正解は解決策の一部を示しています。注: 正解の選択ごとに1ポイントが加算されます。
DP-700 試験問題 49
Warehouse1 という名前の倉庫を含む Fabric ワークスペースがあります。
Warehouse1 で、次のステートメントを実行して DimCustomer という名前のテーブルを作成します。

Customerkey 列を DimCustomer テーブルの主キーとして設定する必要があります。
どの 3 つのコード セグメントを順番に実行する必要がありますか? 回答するには、コード セグメントのリストから適切なコード セグメントを回答領域に移動し、正しい順序に並べます。

Warehouse1 で、次のステートメントを実行して DimCustomer という名前のテーブルを作成します。
Customerkey 列を DimCustomer テーブルの主キーとして設定する必要があります。
どの 3 つのコード セグメントを順番に実行する必要がありますか? 回答するには、コード セグメントのリストから適切なコード セグメントを回答領域に移動し、正しい順序に並べます。

DP-700 試験問題 50
Lakehouse1 という名前のレイクハウスを含む Fabric ワークスペースがあります。Lakehouse1 には、Table1 という名前の Delta テーブルが含まれています。
Table1 を分析すると、Table1 にはそれぞれ 1 MB の Parquet ファイルが 2,000 個含まれていることがわかります。
Table1 のクエリにかかる時間を最小限に抑える必要があります。
何をすべきでしょうか?
Table1 を分析すると、Table1 にはそれぞれ 1 MB の Parquet ファイルが 2,000 個含まれていることがわかります。
Table1 のクエリにかかる時間を最小限に抑える必要があります。
何をすべきでしょうか?