
DP-203 試験問題 146
Table1という名前のテーブルを含むAzureSynapseAnalytics専用のSQLプールがあります。
container1という名前のAzureDataLakeStorageGen2コンテナーに取り込まれてロードされるファイルがあります。
ファイルからTable1にデータを挿入し、container1という名前のData LakeStorageGen2コンテナを紺碧にする予定です。
ファイルからTable1にデータを挿入し、データを変換することを計画しています。ファイル内のデータの各行は、Table1のサービングレイヤーに1つの行を生成します。
ソースデータファイルがcontainer1にロードされるときに、DateTimeが追加の列としてTable1に格納されていることを確認する必要があります。
解決策:Azure Synapse Analyticsパイプラインでは、ファイルの日時を取得するメタデータの取得アクティビティを使用します。
これは目標を達成していますか?
container1という名前のAzureDataLakeStorageGen2コンテナーに取り込まれてロードされるファイルがあります。
ファイルからTable1にデータを挿入し、container1という名前のData LakeStorageGen2コンテナを紺碧にする予定です。
ファイルからTable1にデータを挿入し、データを変換することを計画しています。ファイル内のデータの各行は、Table1のサービングレイヤーに1つの行を生成します。
ソースデータファイルがcontainer1にロードされるときに、DateTimeが追加の列としてTable1に格納されていることを確認する必要があります。
解決策:Azure Synapse Analyticsパイプラインでは、ファイルの日時を取得するメタデータの取得アクティビティを使用します。
これは目標を達成していますか?
DP-203 試験問題 147
WS1という名前のAzureSynapseAnalyticsワークスペースがあります。
次の形式のJSON形式のファイルを含むAzureDataLakeStorageGen2コンテナーがあります。

ファイルを読み取るには、WS1のサーバーレスSQLプールを使用する必要があります。
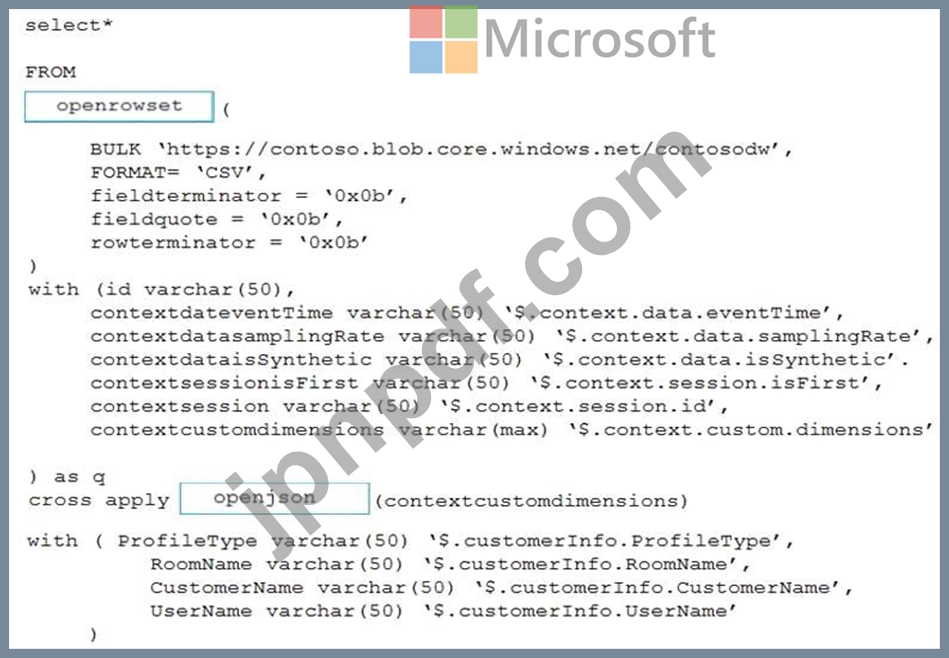
Transact-SQLステートメントをどのように完了する必要がありますか?答えるには、適切な値を正しいターゲットにドラッグします。各値は、1回使用することも、複数回使用することも、まったく使用しないこともできます。コンテンツを表示するには、ペイン間で分割バーをドラッグするか、スクロールする必要がある場合があります。
注:正しい選択はそれぞれ1ポイントの価値があります。
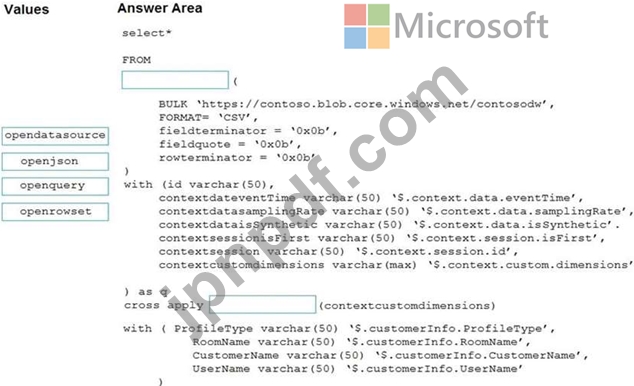
次の形式のJSON形式のファイルを含むAzureDataLakeStorageGen2コンテナーがあります。
ファイルを読み取るには、WS1のサーバーレスSQLプールを使用する必要があります。
Transact-SQLステートメントをどのように完了する必要がありますか?答えるには、適切な値を正しいターゲットにドラッグします。各値は、1回使用することも、複数回使用することも、まったく使用しないこともできます。コンテンツを表示するには、ペイン間で分割バーをドラッグするか、スクロールする必要がある場合があります。
注:正しい選択はそれぞれ1ポイントの価値があります。

DP-203 試験問題 148
Azureデータブリックスを使用してPurchasesという名前のデータセットを開発する予定です。Purchasesには次の列が含まれます。
* 製品番号
*ItemPrice
* lineTotal
* 量
* StorelD
* 分
* 月
* 時間
* 年
* 日
StoreIDごとに異なる1時間ごとの増分ロードパイプラインをサポートするために、データを保存する必要があります。ソリューションはストレージコストを最小限に抑える必要があります。どのように乗り物を完成させる必要がありますか?回答するには、回答エリアで適切なオプションを選択します。
注:正しい選択はそれぞれ1ポイントの価値があります。

* 製品番号
*ItemPrice
* lineTotal
* 量
* StorelD
* 分
* 月
* 時間
* 年
* 日
StoreIDごとに異なる1時間ごとの増分ロードパイプラインをサポートするために、データを保存する必要があります。ソリューションはストレージコストを最小限に抑える必要があります。どのように乗り物を完成させる必要がありますか?回答するには、回答エリアで適切なオプションを選択します。
注:正しい選択はそれぞれ1ポイントの価値があります。


DP-203 試験問題 149
AzureSynapseAnalytics専用のSQLプールにパーティションテーブルを作成する必要があります。
Transact-SQLステートメントをどのように完了する必要がありますか?答えるには、適切な値を正しいターゲットにドラッグします。各値は、1回使用することも、複数回使用することも、まったく使用しないこともできます。コンテンツを表示するには、ペイン間で分割バーをドラッグするか、スクロールする必要がある場合があります。
注:正しい選択はそれぞれ1ポイントの価値があります。

Transact-SQLステートメントをどのように完了する必要がありますか?答えるには、適切な値を正しいターゲットにドラッグします。各値は、1回使用することも、複数回使用することも、まったく使用しないこともできます。コンテンツを表示するには、ペイン間で分割バーをドラッグするか、スクロールする必要がある場合があります。
注:正しい選択はそれぞれ1ポイントの価値があります。

DP-203 試験問題 150
AzureSynapseAnalytics専用のSQLプールでFactPurchaseという名前のファクトテーブルを設計しています。この表には、小売店のサプライヤーからの購入が含まれています。FactPurchaseには、次の列が含まれます。
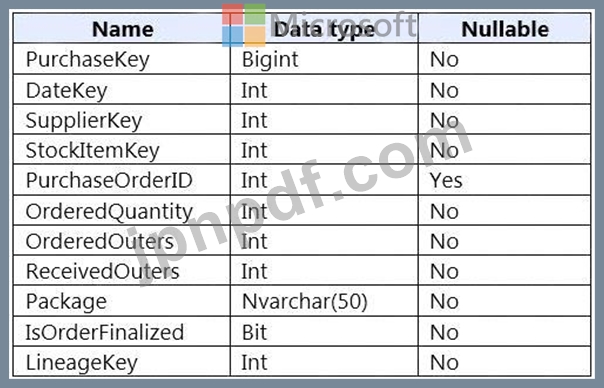
FactPurchaseには、毎日100万行のデータが追加され、3年間のデータが含まれます。
次のクエリと同様のTransact-SQLクエリが毎日実行されます。
選択する
SupplierKey、StockItemKey、COUNT(*)
FactPurchaseから
WHERE DateKey> = 20210101
AND DateKey <= 20210131
GROUP BY SupplierKey、StockItemKey
クエリ時間を最小限に抑えるテーブル配布はどれですか?
FactPurchaseには、毎日100万行のデータが追加され、3年間のデータが含まれます。
次のクエリと同様のTransact-SQLクエリが毎日実行されます。
選択する
SupplierKey、StockItemKey、COUNT(*)
FactPurchaseから
WHERE DateKey> = 20210101
AND DateKey <= 20210131
GROUP BY SupplierKey、StockItemKey
クエリ時間を最小限に抑えるテーブル配布はどれですか?