
DP-100 試験問題 31
注: この質問は、同じシナリオを提示する一連の質問の一部です。一連の質問にはそれぞれ、定められた目標を満たす可能性のある独自の解答が含まれています。質問セットによっては、複数の正解が存在する場合もあれば、正解がない場合もあります。
このセクションの質問に回答した後は、その質問に戻ることはできません。そのため、これらの質問はレビュー画面に表示されません。
履歴データに基づいて気象状況を予測するモデルを作成します。
データストアからデータを読み込み、処理済みのデータを機械学習モデルのトレーニング スクリプトに渡す処理スクリプトを実行するパイプラインを作成する必要があります。
解決策: 次のコードを実行します。
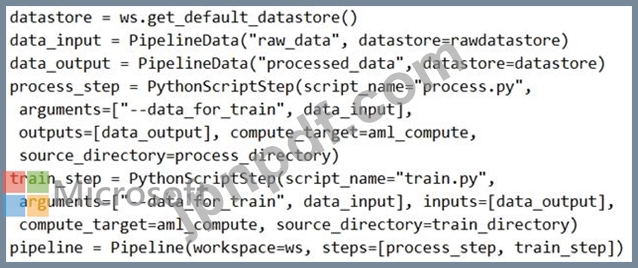
ソリューションは目標を満たしていますか?
このセクションの質問に回答した後は、その質問に戻ることはできません。そのため、これらの質問はレビュー画面に表示されません。
履歴データに基づいて気象状況を予測するモデルを作成します。
データストアからデータを読み込み、処理済みのデータを機械学習モデルのトレーニング スクリプトに渡す処理スクリプトを実行するパイプラインを作成する必要があります。
解決策: 次のコードを実行します。
ソリューションは目標を満たしていますか?
DP-100 試験問題 32
Azure Machine Learning ワークスペースを管理します。開発環境は、Azure Machine Learning Notebooks の Serverless Spark コンピューティングで構成されています。
インタラクティブなデータ ラングリングを実行して、Titanic データセットをクリーンアップし、新しいデータセットとして保存します (行番号は参照用にのみ使用されます)。

次の各文について、正しい場合は「はい」を選択し、そうでない場合は「いいえ」を選択します。注: 正しい選択ごとに 1 ポイントの価値があります。

インタラクティブなデータ ラングリングを実行して、Titanic データセットをクリーンアップし、新しいデータセットとして保存します (行番号は参照用にのみ使用されます)。
次の各文について、正しい場合は「はい」を選択し、そうでない場合は「いいえ」を選択します。注: 正しい選択ごとに 1 ポイントの価値があります。


DP-100 試験問題 33
データセットの構造が一致するように、メタデータ編集モジュールを構成する必要があります。どの構成オプションを選択する必要がありますか?回答するには、回答エリアで適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが加算されます。


注意: 正しい選択ごとに 1 ポイントが加算されます。


DP-100 試験問題 34
Azureストレージアカウント内のBLOBコンテナーを参照する「training_data」というデータストアを作成します。BLOBコンテナーには「csv_files」というフォルダーが含まれており、そこに複数のコンマ区切り値(CSV)ファイルが格納されます。
ローカルフォルダ ./script に train.py というスクリプトがあり、これを推定器を使った実験として実行する予定です。このスクリプトには、csv_files フォルダからデータを読み取るための以下のコードが含まれています。

次のスクリプトがあります。

スクリプトが training_data データストアの csv_files フォルダーを参照する data_ref という名前のデータ参照からデータを読み取ることができるように、実験の推定値を構成する必要があります。
推定値を構成するにはどのコードを使用する必要がありますか?

ローカルフォルダ ./script に train.py というスクリプトがあり、これを推定器を使った実験として実行する予定です。このスクリプトには、csv_files フォルダからデータを読み取るための以下のコードが含まれています。
次のスクリプトがあります。
スクリプトが training_data データストアの csv_files フォルダーを参照する data_ref という名前のデータ参照からデータを読み取ることができるように、実験の推定値を構成する必要があります。
推定値を構成するにはどのコードを使用する必要がありますか?
DP-100 試験問題 35
人が病気にかかっているかどうかを予測するためのバイナリ分類モデルを作成します。
起こりうる分類エラーを検出する必要があります。
それぞれの説明に対してどのエラータイプを選択する必要がありますか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが加算されます。

起こりうる分類エラーを検出する必要があります。
それぞれの説明に対してどのエラータイプを選択する必要がありますか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが加算されます。


