
DP-100 試験問題 231
Azure Machine Learningワークスペースを作成します
ワークスペースでカスタムモデルのトレーニングを実行するためのPython SDK v2ノートブックを開発しています。ノートブックのコードは必要なパッケージをすべてインポートします。
トレーニング スクリプト、環境、およびコンピューティング情報を含めるように Python SDK v2 コードを完成させる必要があります。
10 個のコードをどのように完成させるべきでしょうか? 回答するには、回答エリアで適切なオプションを選択してください。
注: 正解ごとに1ポイント獲得

ワークスペースでカスタムモデルのトレーニングを実行するためのPython SDK v2ノートブックを開発しています。ノートブックのコードは必要なパッケージをすべてインポートします。
トレーニング スクリプト、環境、およびコンピューティング情報を含めるように Python SDK v2 コードを完成させる必要があります。
10 個のコードをどのように完成させるべきでしょうか? 回答するには、回答エリアで適切なオプションを選択してください。
注: 正解ごとに1ポイント獲得

DP-100 試験問題 232
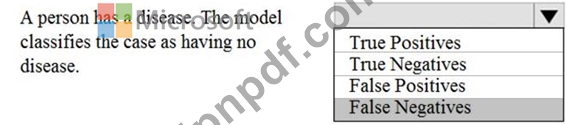
人が病気にかかっているかどうかを予測するためのバイナリ分類モデルを作成します。
起こりうる分類エラーを検出する必要があります。
それぞれの説明に対してどのエラータイプを選択する必要がありますか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが加算されます。

起こりうる分類エラーを検出する必要があります。
それぞれの説明に対してどのエラータイプを選択する必要がありますか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが加算されます。

DP-100 試験問題 233
Azure ML SDKを使用してバッチ推論パイプラインを作成します。パイプラインを実行するには、次のコードを使用します。
azureml.pipeline.core からパイプラインをインポートします
azureml.core.experimentからExperimentをインポートする
パイプライン = パイプライン(ワークスペース = ws、ステップ = [parallelrun_step])
pipeline_run = Experiment(ws, 'batch_pipeline').submit(パイプライン)
パイプライン実行の進行状況を監視する必要があります。
この目標を達成するには、どのような 2 つの方法がありますか? それぞれの正解は完全な解決策を示しています。
注意: 正しい選択ごとに 1 ポイントが加算されます。

azureml.pipeline.core からパイプラインをインポートします
azureml.core.experimentからExperimentをインポートする
パイプライン = パイプライン(ワークスペース = ws、ステップ = [parallelrun_step])
pipeline_run = Experiment(ws, 'batch_pipeline').submit(パイプライン)
パイプライン実行の進行状況を監視する必要があります。
この目標を達成するには、どのような 2 つの方法がありますか? それぞれの正解は完全な解決策を示しています。
注意: 正しい選択ごとに 1 ポイントが加算されます。
DP-100 試験問題 234
注: この質問は、同じシナリオを提示する一連の質問の一部です。一連の質問にはそれぞれ、定められた目標を満たす可能性のある独自の解答が含まれています。質問セットによっては、複数の正解が存在する場合もあれば、正解がない場合もあります。
このセクションの質問に回答した後は、その質問に戻ることはできません。そのため、これらの質問はレビュー画面に表示されません。
Azure Machine Learning Studio で新しい実験を作成しています。
1 つのクラスには、トレーニング セット内の他のクラスよりも観測数が大幅に少なくなっています。
クラスの不均衡を補うには、適切なデータ サンプリング戦略を選択する必要があります。
解決策: スケールおよび削減サンプリング モードを使用します。
ソリューションは目標を満たしていますか?
このセクションの質問に回答した後は、その質問に戻ることはできません。そのため、これらの質問はレビュー画面に表示されません。
Azure Machine Learning Studio で新しい実験を作成しています。
1 つのクラスには、トレーニング セット内の他のクラスよりも観測数が大幅に少なくなっています。
クラスの不均衡を補うには、適切なデータ サンプリング戦略を選択する必要があります。
解決策: スケールおよび削減サンプリング モードを使用します。
ソリューションは目標を満たしていますか?
DP-100 試験問題 235
分類モデルをトレーニングするデータを含むコンマ区切り値 (CSV) ファイルがあります。
Azure Machine Learning Studio の自動機械学習インターフェースを使用して分類モデルをトレーニングします。タスクの種類は「分類」に設定します。
自動機械学習プロセスでは線形モデルのみが評価されるようにする必要があります。
何をすべきでしょうか?
Azure Machine Learning Studio の自動機械学習インターフェースを使用して分類モデルをトレーニングします。タスクの種類は「分類」に設定します。
自動機械学習プロセスでは線形モデルのみが評価されるようにする必要があります。
何をすべきでしょうか?