DP-100 試験問題 261
モデルのトレーニング時に選択したハイパーパラメーターを最適化するために Hyperdrive を使用する予定です。次のコードを作成して、ハイパーパラメータ実験のオプションを定義します。


次の各ステートメントについて、そのステートメントが true の場合は [はい] を選択します。それ以外の場合は、「いいえ」を選択します。 注: 正しく選択するたびに 1 ポイントの価値があります。

次の各ステートメントについて、そのステートメントが true の場合は [はい] を選択します。それ以外の場合は、「いいえ」を選択します。 注: 正しく選択するたびに 1 ポイントの価値があります。

DP-100 試験問題 262
注: この質問は、同じシナリオを示す一連の質問の一部です。このシリーズの各質問には、指定された目標を達成できる可能性のある独自の解決策が含まれています。一部の質問セットには複数の正しい解決策が含まれる場合がありますが、他の質問セットには正しい解決策がない場合があります。
このセクションの質問に回答すると、その質問に戻ることはできません。そのため、これらの質問はレビュー画面には表示されません。
いくつかの列に欠損値を含む数値データセットを分析しています。
特徴セットの次元に影響を与えずに、適切な操作を使用して欠損値をクリーンアップする必要があります。
すべての値を含めるには、完全なデータセットを分析する必要があります。
解決策: 列の中央値を計算し、その中央値を列内の欠損値の置換として使用します。
解決策は目標を達成できますか?
このセクションの質問に回答すると、その質問に戻ることはできません。そのため、これらの質問はレビュー画面には表示されません。
いくつかの列に欠損値を含む数値データセットを分析しています。
特徴セットの次元に影響を与えずに、適切な操作を使用して欠損値をクリーンアップする必要があります。
すべての値を含めるには、完全なデータセットを分析する必要があります。
解決策: 列の中央値を計算し、その中央値を列内の欠損値の置換として使用します。
解決策は目標を達成できますか?
DP-100 試験問題 263
train.py という名前の Python スクリプトを作成し、scripts という名前のフォルダーに保存します。このスクリプトは、scikit-learn フレームワークを使用して機械学習モデルをトレーニングします。
ローカル ワークステーションで Azure Machine Learning 実験としてスクリプトを実行する必要があります。
train.py スクリプトを実行する実験を開始するには、Python コードを作成する必要があります。
コードセグメントをどのように完成させるべきでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。

ローカル ワークステーションで Azure Machine Learning 実験としてスクリプトを実行する必要があります。
train.py スクリプトを実行する実験を開始するには、Python コードを作成する必要があります。
コードセグメントをどのように完成させるべきでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。


DP-100 試験問題 264
マルチクラス分類タスク用に作成されたデータセットには、10,000 個のデータ ポイントと 150 個の特徴を含む正規化された数値特徴セットが含まれています。
データ ポイントの 75 パーセントをトレーニングに使用し、25 パーセントをテストに使用します。Python で scikit-learn 機械学習ライブラリを使用しています。X を使用して機能セットを示し、Y を使用してクラス ラベルを示します。
次の Python データ フレームを作成します。
主成分分析 (PCA) メソッドを適用して、トレーニング セットとテスト セットの両方で特徴セットの次元を 10 個の特徴に減らす必要があります。
コードセグメントをどのように完成させるべきでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。

データ ポイントの 75 パーセントをトレーニングに使用し、25 パーセントをテストに使用します。Python で scikit-learn 機械学習ライブラリを使用しています。X を使用して機能セットを示し、Y を使用してクラス ラベルを示します。
次の Python データ フレームを作成します。
主成分分析 (PCA) メソッドを適用して、トレーニング セットとテスト セットの両方で特徴セットの次元を 10 個の特徴に減らす必要があります。
コードセグメントをどのように完成させるべきでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。


DP-100 試験問題 265
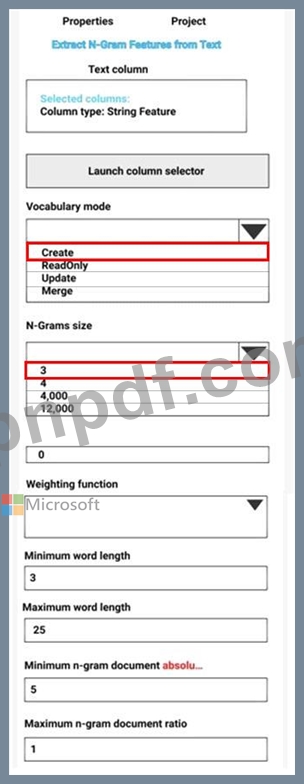
あなたは、短文形式で書かれた 12,000 件の顧客レビューを含む CSV ファイルを使用してセンチメント分析を実行しています。CSV ファイルを Azure Machine Learning Studio に追加し、実験の開始点データセットとして構成します。テキストから N グラム特徴を抽出モジュールを実験に追加して、データセットの顧客レビュー列からキー フレーズを抽出します。
カスタマー レビュー テキストから新しい N-gram 辞書を作成し、最大 N-gram サイズをトリグラムに設定する必要があります。
何を選択すればよいでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。

カスタマー レビュー テキストから新しい N-gram 辞書を作成し、最大 N-gram サイズをトリグラムに設定する必要があります。
何を選択すればよいでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。