
DP-100 試験問題 221
機械学習モデルをトレーニングします。
モデルをテスト用のリアルタイム推論サービスとしてデプロイする必要があります。このサービスには、低い CPU 使用率と 48 MB 未満の RAM が必要です。デプロイされたサービスのコンピューティング ターゲットは、コストと管理オーバーヘッドを最小限に抑えながら、自動的に初期化される必要があります。
どのコンピューティング ターゲットを使用する必要がありますか?
モデルをテスト用のリアルタイム推論サービスとしてデプロイする必要があります。このサービスには、低い CPU 使用率と 48 MB 未満の RAM が必要です。デプロイされたサービスのコンピューティング ターゲットは、コストと管理オーバーヘッドを最小限に抑えながら、自動的に初期化される必要があります。
どのコンピューティング ターゲットを使用する必要がありますか?
DP-100 試験問題 222
注: この質問は、同じシナリオを示す一連の質問の一部です。このシリーズの各質問には、指定された目標を達成できる可能性のある独自の解決策が含まれています。一部の質問セットには複数の正しい解決策が含まれる場合がありますが、他の質問セットには正しい解決策がない場合があります。
このセクションの質問に回答すると、その質問に戻ることはできません。そのため、これらの質問はレビュー画面には表示されません。
Azure Machine Learning サービス データストアをワークスペースに作成します。データストアには次のファイルが含まれています。
* /data/2018/Q1 .csv
* /data/2018/Q2.csv
* /data/2018/Q3.csv
* /data/2018/Q4.csv
* /data/2019/Q1.csv
すべてのファイルには次の形式でデータが保存されます。
id,M,f2,l
1、1、2、0
2,1,1,1
32,10
次のコードを実行します。

次のコードを使用して、training_data という名前のデータセットを作成し、すべてのファイルから単一のデータ フレームにデータをロードする必要があります。

解決策: 次のコードを実行します。

解決策は目標を達成できますか?
このセクションの質問に回答すると、その質問に戻ることはできません。そのため、これらの質問はレビュー画面には表示されません。
Azure Machine Learning サービス データストアをワークスペースに作成します。データストアには次のファイルが含まれています。
* /data/2018/Q1 .csv
* /data/2018/Q2.csv
* /data/2018/Q3.csv
* /data/2018/Q4.csv
* /data/2019/Q1.csv
すべてのファイルには次の形式でデータが保存されます。
id,M,f2,l
1、1、2、0
2,1,1,1
32,10
次のコードを実行します。
次のコードを使用して、training_data という名前のデータセットを作成し、すべてのファイルから単一のデータ フレームにデータをロードする必要があります。
解決策: 次のコードを実行します。
解決策は目標を達成できますか?
DP-100 試験問題 223
統計分布の非対称性を分析しています。
次の画像には、2 つのデータセットの確率分布を示す 2 つの密度曲線が含まれています。
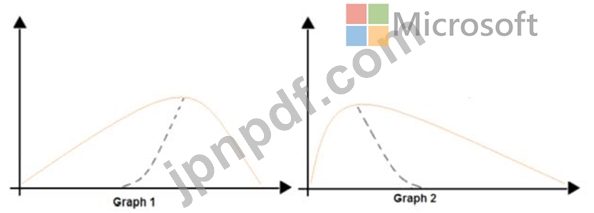
ドロップダウン メニューを使用して、図に示されている情報に基づいて各質問に答える回答の選択肢を選択します。
注: 正しく選択するたびに 1 ポイントの価値があります。

次の画像には、2 つのデータセットの確率分布を示す 2 つの密度曲線が含まれています。
ドロップダウン メニューを使用して、図に示されている情報に基づいて各質問に答える回答の選択肢を選択します。
注: 正しく選択するたびに 1 ポイントの価値があります。

DP-100 試験問題 224
STANDARD_D1 仮想マシン イメージを使用して、ComputeOne という名前の Azure Machine Learning コンピューティング ターゲットを作成します。
Azure Machine Learning ワークスペースを参照する was という名前の Python 変数を定義します。次の Python コードを実行します。

次の各ステートメントについて、そのステートメントが true の場合は [はい] を選択します。それ以外の場合は、「いいえ」を選択します。
注: 正しく選択するたびに 1 ポイントの価値があります。

Azure Machine Learning ワークスペースを参照する was という名前の Python 変数を定義します。次の Python コードを実行します。
次の各ステートメントについて、そのステートメントが true の場合は [はい] を選択します。それ以外の場合は、「いいえ」を選択します。
注: 正しく選択するたびに 1 ポイントの価値があります。


DP-100 試験問題 225
注: この質問は、同じシナリオを示す一連の質問の一部です。このシリーズの各質問には、指定された目標を達成できる可能性のある独自の解決策が含まれています。一部の質問セットには複数の正しい解決策が含まれる場合がありますが、他の質問セットには正しい解決策がない場合があります。
このセクションの質問に回答すると、その質問に戻ることはできません。そのため、これらの質問はレビュー画面には表示されません。
いくつかの列に欠損値を含む数値データセットを分析しています。
特徴セットの次元に影響を与えずに、適切な操作を使用して欠損値をクリーンアップする必要があります。
すべての値を含めるには、完全なデータセットを分析する必要があります。
解決策: Last Observation Carried Forward (IOCF) メソッドを使用して、欠落しているデータ ポイントを代入します。
解決策は目標を達成できますか?
このセクションの質問に回答すると、その質問に戻ることはできません。そのため、これらの質問はレビュー画面には表示されません。
いくつかの列に欠損値を含む数値データセットを分析しています。
特徴セットの次元に影響を与えずに、適切な操作を使用して欠損値をクリーンアップする必要があります。
すべての値を含めるには、完全なデータセットを分析する必要があります。
解決策: Last Observation Carried Forward (IOCF) メソッドを使用して、欠落しているデータ ポイントを代入します。
解決策は目標を達成できますか?
