
DP-100 試験問題 256

次の各ステートメントについて、ステートメントがtrueの場合は、[はい]を選択します。それ以外の場合は、[いいえ]を選択します。注:正しい選択はそれぞれ1ポイントの価値があります。


DP-100 試験問題 257
AzureMachineLearningワークスペースでモデルをトレーニングして登録します。
クライアントアプリケーションがバッチ推論にモデルを使用できるようにするパイプラインを公開する必要があります。入力データから予測を取得するには、Python推論スクリプトを実行する単一のParallelRunStepステップでパイプラインを使用する必要があります。
ParallelRunStepパイプラインステップの推論スクリプトを作成する必要があります。
どの2つの機能を含める必要がありますか?それぞれの正解は、解決策の一部を示しています。
注:正しい選択はそれぞれ1ポイントの価値があります。
クライアントアプリケーションがバッチ推論にモデルを使用できるようにするパイプラインを公開する必要があります。入力データから予測を取得するには、Python推論スクリプトを実行する単一のParallelRunStepステップでパイプラインを使用する必要があります。
ParallelRunStepパイプラインステップの推論スクリプトを作成する必要があります。
どの2つの機能を含める必要がありますか?それぞれの正解は、解決策の一部を示しています。
注:正しい選択はそれぞれ1ポイントの価値があります。
DP-100 試験問題 258
アルゴリズムのハイパーパラメータを調整しています。次の表は、さまざまなハイパーパラメータ、トレーニングエラー、および検証エラーを含むデータセットを示しています。
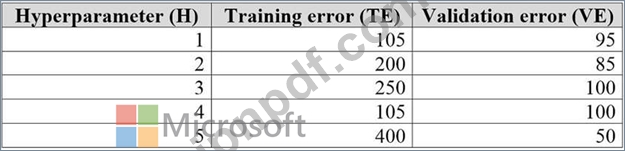
ドロップダウンメニューを使用して、図に示されている情報に基づいて各質問に回答する回答の選択肢を選択します。
ドロップダウンメニューを使用して、図に示されている情報に基づいて各質問に回答する回答の選択肢を選択します。
DP-100 試験問題 259
AzureのWindowsおよびLinux用のデータサイエンス仮想マシン(DSVM)を使用します。
DSVMにアクセスする必要があります。
どのユーティリティを使用する必要がありますか?回答するには、回答エリアで適切なオプションを選択してください。
注:正しい選択はそれぞれ1ポイントの価値があります。

DSVMにアクセスする必要があります。
どのユーティリティを使用する必要がありますか?回答するには、回答エリアで適切なオプションを選択してください。
注:正しい選択はそれぞれ1ポイントの価値があります。

DP-100 試験問題 260
注:この質問は、同じシナリオを提示する一連の質問の一部です。シリーズの各質問には、述べられた目標を達成する可能性のある独自の解決策が含まれています。一部の質問セットには複数の正しい解決策がある場合がありますが、他の質問セットには正しい解決策がない場合があります。
このセクションの質問に回答した後は、その質問に戻ることはできません。その結果、これらの質問はレビュー画面に表示されません。
Pythonスクリプトを使用して、AzureMachineLearningの実験を実行することを計画しています。スクリプトは、実験実行コンテキストへの参照を作成し、ファイルからデータをロードし、ラベル列の一意の値のセットを識別して、実験実行を完了します。
azureml.coreからインポート実行
パンダをpdとしてインポートします
run = Run.get_context()
data = pd.read_csv('data.csv')
label_vals = data ['label']。unique()
#ここに指標を記録するコードを追加
run.complete()
実験では、後で確認できる実行のメトリックとして、データに一意のラベルを記録する必要があります。
コメントで示されたポイントで実行メトリックとして一意のラベル値を記録するには、スクリプトにコードを追加する必要があります。
解決策:コメントを次のコードに置き換えます。
run.log_table('ラベル値'、label_vals)
ソリューションは目標を達成していますか?
このセクションの質問に回答した後は、その質問に戻ることはできません。その結果、これらの質問はレビュー画面に表示されません。
Pythonスクリプトを使用して、AzureMachineLearningの実験を実行することを計画しています。スクリプトは、実験実行コンテキストへの参照を作成し、ファイルからデータをロードし、ラベル列の一意の値のセットを識別して、実験実行を完了します。
azureml.coreからインポート実行
パンダをpdとしてインポートします
run = Run.get_context()
data = pd.read_csv('data.csv')
label_vals = data ['label']。unique()
#ここに指標を記録するコードを追加
run.complete()
実験では、後で確認できる実行のメトリックとして、データに一意のラベルを記録する必要があります。
コメントで示されたポイントで実行メトリックとして一意のラベル値を記録するには、スクリプトにコードを追加する必要があります。
解決策:コメントを次のコードに置き換えます。
run.log_table('ラベル値'、label_vals)
ソリューションは目標を達成していますか?