
DP-100 試験問題 231
次の形式のsalesDataという名前のPythonデータフレームがあります。

データフレームは、次のように長いデータ形式にピボット解除する必要があります。
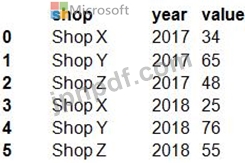
変換を実行するには、Pythonでpandas.melt()関数を使用する必要があります。
コードセグメントをどのように完成させる必要がありますか?回答するには、回答エリアで適切なオプションを選択してください。
注:正しい選択はそれぞれ1ポイントの価値があります。

データフレームは、次のように長いデータ形式にピボット解除する必要があります。
変換を実行するには、Pythonでpandas.melt()関数を使用する必要があります。
コードセグメントをどのように完成させる必要がありますか?回答するには、回答エリアで適切なオプションを選択してください。
注:正しい選択はそれぞれ1ポイントの価値があります。

DP-100 試験問題 232
X、Y、およびZの数値機能を含む機能セットがあります。
X、Y、およびZフィーチャのポアソン相関係数(r値)を次の画像に示します。

ドロップダウンメニューを使用して、図に示されている情報に基づいて各質問に回答する回答の選択肢を選択します。
注:正しい選択はそれぞれ1ポイントの価値があります。

X、Y、およびZフィーチャのポアソン相関係数(r値)を次の画像に示します。
ドロップダウンメニューを使用して、図に示されている情報に基づいて各質問に回答する回答の選択肢を選択します。
注:正しい選択はそれぞれ1ポイントの価値があります。

DP-100 試験問題 233
Azure Machine Learning Designerを使用して、機械学習モデルを作成します。モデルをAzureKubernetesService(AKS)推論コンピューティングクラスターでリアルタイムサービスとして公開します。デプロイされたエンドポイント構成に変更を加えることはありません。
アプリケーション開発者に、エンドポイントを使用するために必要な情報を提供する必要があります。
アプリケーション開発者に提供する必要がある2つの値はどれですか?それぞれの正解は、解決策の一部を示しています。
注:正しい選択はそれぞれ1ポイントの価値があります。
アプリケーション開発者に、エンドポイントを使用するために必要な情報を提供する必要があります。
アプリケーション開発者に提供する必要がある2つの値はどれですか?それぞれの正解は、解決策の一部を示しています。
注:正しい選択はそれぞれ1ポイントの価値があります。
DP-100 試験問題 234
マルチクラスの画像分類深層学習モデルを作成します。
モデルは、公開Webポータルから取得した新しい画像データを使用して毎月再トレーニングする必要があります。Azure Machine Learningパイプラインを作成して、新しいデータをフェッチし、画像のサイズを標準化し、モデルを再トレーニングします。
パイプラインのスケジュールを構成するには、Azure MachineLearningSDKを使用する必要があります。
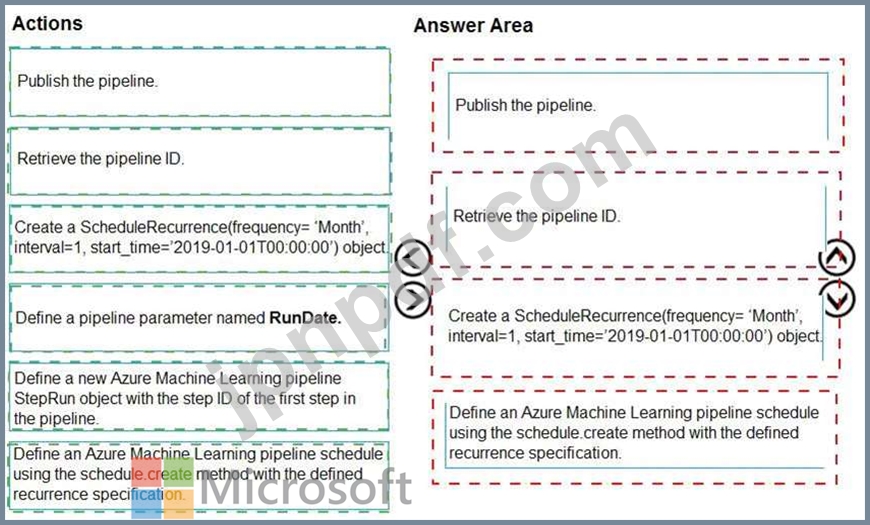
順番に実行する必要がある4つのアクションはどれですか?回答するには、適切なアクションをアクションのリストから回答領域に移動し、正しい順序に並べます。

モデルは、公開Webポータルから取得した新しい画像データを使用して毎月再トレーニングする必要があります。Azure Machine Learningパイプラインを作成して、新しいデータをフェッチし、画像のサイズを標準化し、モデルを再トレーニングします。
パイプラインのスケジュールを構成するには、Azure MachineLearningSDKを使用する必要があります。
順番に実行する必要がある4つのアクションはどれですか?回答するには、適切なアクションをアクションのリストから回答領域に移動し、正しい順序に並べます。

DP-100 試験問題 235
AzureStorageアカウントのBLOBコンテナーを参照するtraining_dataという名前のデータストアを作成します。blobコンテナーには、複数のコンマ区切り値(CSV)ファイルが保管されているという名前のフォルダーが含まれています。
./scriptという名前のローカルフォルダーにtrain.pyという名前のスクリプトがあり、推定器を使用して実験として実行する予定です。スクリプトには、csv_filesフォルダーからデータを読み取るための次のコードが含まれています。

次のスクリプトがあります。

スクリプトがtraining_dataデータストアのcsv_filesフォルダーを参照するdata_refという名前のデータ参照からデータを読み取ることができるように、実験の推定器を構成する必要があります。
Estimatorを構成するためにどのコードを使用する必要がありますか?

./scriptという名前のローカルフォルダーにtrain.pyという名前のスクリプトがあり、推定器を使用して実験として実行する予定です。スクリプトには、csv_filesフォルダーからデータを読み取るための次のコードが含まれています。
次のスクリプトがあります。
スクリプトがtraining_dataデータストアのcsv_filesフォルダーを参照するdata_refという名前のデータ参照からデータを読み取ることができるように、実験の推定器を構成する必要があります。
Estimatorを構成するためにどのコードを使用する必要がありますか?