
DP-100 試験問題 221
音声認識ディープラーニングモデルを作成する予定です。
モデルは最新バージョンのPythonをサポートしている必要があります。
データサイエンス仮想マシン(DSVM)に含めるには、音声認識用の深層学習フレームワークを推奨する必要があります。
何をお勧めしますか?
モデルは最新バージョンのPythonをサポートしている必要があります。
データサイエンス仮想マシン(DSVM)に含めるには、音声認識用の深層学習フレームワークを推奨する必要があります。
何をお勧めしますか?
DP-100 試験問題 222
注:この質問は、同じシナリオを提示する一連の質問の一部です。シリーズの各質問には、述べられた目標を達成する可能性のある独自の解決策が含まれています。一部の質問セットには複数の正しい解決策がある場合がありますが、他の質問セットには正しい解決策がない場合があります。
このセクションの質問に回答した後は、その質問に戻ることはできません。その結果、これらの質問はレビュー画面に表示されません。
Azure Machine Learningを使用して、分類モデルをトレーニングする実験を実行しています。
Hyperdriveを使用して、モデルのAUCメトリックを最適化するパラメーターを検索します。次のコードを実行して、実験用にHyperDriveConfigを構成します。

y_test変数という名前の変数、およびモデルから予測された確率は、y_predictedという名前の変数に格納されます。HyperdriveがAUCメトリックのハイパーパラメータを最適化できるようにするには、スクリプトにログを追加する必要があります。解決策:次のコードを実行します。

ソリューションは目標を達成していますか?
このセクションの質問に回答した後は、その質問に戻ることはできません。その結果、これらの質問はレビュー画面に表示されません。
Azure Machine Learningを使用して、分類モデルをトレーニングする実験を実行しています。
Hyperdriveを使用して、モデルのAUCメトリックを最適化するパラメーターを検索します。次のコードを実行して、実験用にHyperDriveConfigを構成します。
y_test変数という名前の変数、およびモデルから予測された確率は、y_predictedという名前の変数に格納されます。HyperdriveがAUCメトリックのハイパーパラメータを最適化できるようにするには、スクリプトにログを追加する必要があります。解決策:次のコードを実行します。
ソリューションは目標を達成していますか?
DP-100 試験問題 223
Azure MachineLearningStudioで多重線形回帰モデルを作成しています。
いくつかの独立変数は高度に相関しています。
すべてのデータに対して選択的特徴エンジニアリングを実行するための適切な方法を選択する必要があります。
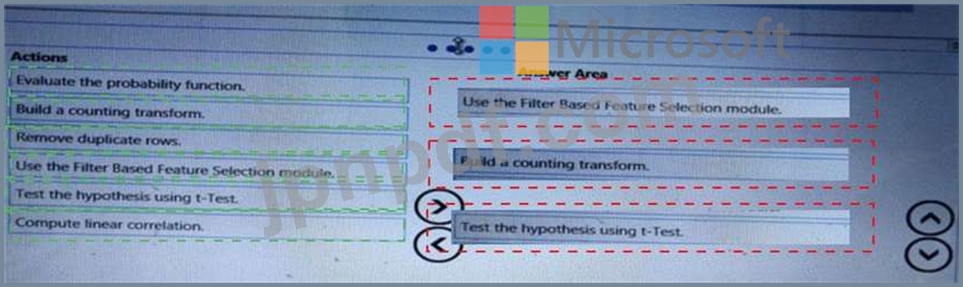
順番に実行する必要がある3つのアクションはどれですか?回答するには、適切なアクションをアクションのリストから回答領域に移動し、正しい順序に並べます。

いくつかの独立変数は高度に相関しています。
すべてのデータに対して選択的特徴エンジニアリングを実行するための適切な方法を選択する必要があります。
順番に実行する必要がある3つのアクションはどれですか?回答するには、適切なアクションをアクションのリストから回答領域に移動し、正しい順序に並べます。
DP-100 試験問題 224
Azure Machine Learningを使用して、機械学習モデルをトレーニングしています。トレーニングスクリプトをリモートで実行するための計算ターゲットが必要です。次のPythonコードを実行します。



DP-100 試験問題 225
あなたのチームは、データエンジニアリングとデータサイエンスの開発環境を構築しています。
環境は、次の要件をサポートする必要があります。
*PythonとScalaをサポート
*データの保存、移動、処理サービスを自動化されたデータパイプラインに構成します
*データエンジニアリングとデータサイエンスの両方のオーケストレーションに同じツールを使用する必要があります
*ワークロードの分離とインタラクティブなワークロードをサポート
*マシンのクラスター全体でのスケーリングを有効にする
環境を作成する必要があります。
あなたは何をするべきか?
環境は、次の要件をサポートする必要があります。
*PythonとScalaをサポート
*データの保存、移動、処理サービスを自動化されたデータパイプラインに構成します
*データエンジニアリングとデータサイエンスの両方のオーケストレーションに同じツールを使用する必要があります
*ワークロードの分離とインタラクティブなワークロードをサポート
*マシンのクラスター全体でのスケーリングを有効にする
環境を作成する必要があります。
あなたは何をするべきか?