
Databricks-Certified-Professional-Data-Scientist 試験問題 36
ロジスティック回帰に適用される正しいステートメントを選択してください
Databricks-Certified-Professional-Data-Scientist 試験問題 37
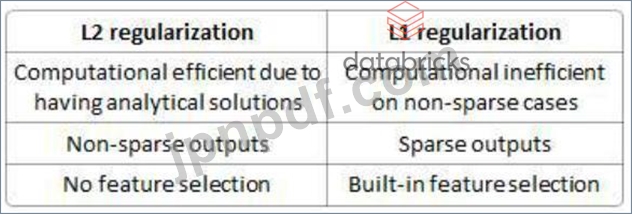
L2正則化に適用される正しいオプションを選択してください
Databricks-Certified-Professional-Data-Scientist 試験問題 38
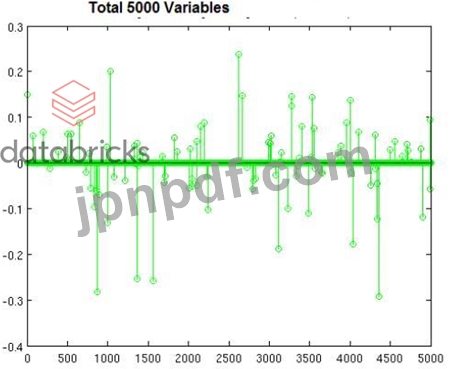
5000個の変数(多くの列、それほど多くの行ではない)を使用して、画像に示されているのと同様の非常に高次元のデータセットから分類器を構築しています。密な入力と疎な入力の両方を処理できます。どの手法が最も適していますか、またその理由は何ですか?
Databricks-Certified-Professional-Data-Scientist 試験問題 39
質問3:機械学習では、(カーネルトリックに類似した)ハッシュトリックとも呼ばれる特徴ハッシュは、特徴(言語の単語など)をベクトル化するための高速でスペース効率の高い方法です。ベクトルまたは行列のインデックスへの任意の特徴。これは、ハッシュ関数を特徴に適用し、連想配列でインデックスを検索するのではなく、特徴の数を法とするハッシュ値をインデックスとして直接使用することで機能します。では、分類子を構築するためのハッシュトリックの主な理由は何ですか?
Databricks-Certified-Professional-Data-Scientist 試験問題 40
k-meansクラスタリングを使用して、病院の心臓病患者を分類しています。指標として患者の性別、身長、体重、年齢、収入を選択し、3つのクラスターを使用しました。クラスターのペアワイズプロットを作成すると、クラスター間にかなりの重複があることに気付きます。あなたは何をするべきか?