
Databricks-Certified-Professional-Data-Scientist 試験問題 1
教師なし学習では、どのステートメントが正しく適用されるか
Databricks-Certified-Professional-Data-Scientist 試験問題 2
分析ライフサイクルのどのフェーズで、プロジェクト時間の大部分を費やすと思いますか?
Databricks-Certified-Professional-Data-Scientist 試験問題 3
機能ハッシュのアプローチは、「SGDベースの分類器は、適切なサイズを選択し、トレーニングデータをそのサイズのベクトルにシューホーニングするだけで、ベクトルサイズを事前に決定する必要がない」というものです。現在、大きなベクトルを使用するか、機能ハッシュの機能ごとに複数の場所を使用しますか?
Databricks-Certified-Professional-Data-Scientist 試験問題 4
特定の食料品店から購入した10,000人のデータがあります。また、データには収入の詳細が含まれています。このデータを使用して5つのクラスターを作成しました。しかし、クラスターの1つでは、30人だけが、30人、2400人、2600人、2700人、2270人などを下回っています。」この場合、どうしますか。
Databricks-Certified-Professional-Data-Scientist 試験問題 5
展示を参照
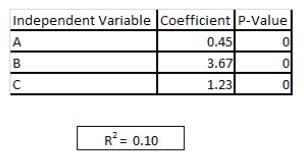
クライアントから提供されたデータセットを使用して、特定の変数がクライアントの売上にどのように影響するかについてのレポートを作成するように求められます。データには、クライアントが売上に直接関連していると見なす15の変数が含まれており、これらの変数のみに制限されています。データの予備分析の後、次の結果が得られました:1。
多重共線性は変数2の間で問題になりません。3つの変数(A、B、およびC)のみが売上と有意な相関関係があります。A、B、およびCの独立変数を使用して、売上の従属変数に線形回帰モデルを作成します。
回帰の結果は展示に見られます。追加のデータをリクエストすることはできません。モデルを人為的に膨らませることなく、モデルのR2を増やす方法は何ですか?
クライアントから提供されたデータセットを使用して、特定の変数がクライアントの売上にどのように影響するかについてのレポートを作成するように求められます。データには、クライアントが売上に直接関連していると見なす15の変数が含まれており、これらの変数のみに制限されています。データの予備分析の後、次の結果が得られました:1。
多重共線性は変数2の間で問題になりません。3つの変数(A、B、およびC)のみが売上と有意な相関関係があります。A、B、およびCの独立変数を使用して、売上の従属変数に線形回帰モデルを作成します。
回帰の結果は展示に見られます。追加のデータをリクエストすることはできません。モデルを人為的に膨らませることなく、モデルのR2を増やす方法は何ですか?