
DP-100 試験問題 1
ノートブックからのモデル トレーニングのハイパーパラメータ チューニングを実装しています。ノートブックは Azure Machine Learning ワークスペースにあります。関連するすべての Python ライブラリをインポートするコードを追加します。
num_hidden_layers および batch_size ハイパーパラメータの検索空間でベイジアン サンプリングを構成する必要があります。
ベイジアン サンプリングを構成するには、次の Python コードを完了する必要があります。
どのコード セグメントを使用する必要がありますか? 回答するには、回答領域で適切なオプションを選択します。注: 正しい選択ごとに 1 ポイントが付与されます。

num_hidden_layers および batch_size ハイパーパラメータの検索空間でベイジアン サンプリングを構成する必要があります。
ベイジアン サンプリングを構成するには、次の Python コードを完了する必要があります。
どのコード セグメントを使用する必要がありますか? 回答するには、回答領域で適切なオプションを選択します。注: 正しい選択ごとに 1 ポイントが付与されます。

DP-100 試験問題 2
Azure Machine Learning ワークスペースを使用します。
次の Python コードを作成します。

次の各文について、正しい場合は「はい」を選択してください。そうでない場合は「いいえ」を選択してください。
注意: 正しい選択ごとに 1 ポイントが付与されます。

次の Python コードを作成します。
次の各文について、正しい場合は「はい」を選択してください。そうでない場合は「いいえ」を選択してください。
注意: 正しい選択ごとに 1 ポイントが付与されます。


DP-100 試験問題 3
提供されたトレーニング セットを使用してバイナリ分類モデルを構築しています。
トレーニング セットは 2 つのクラス間で不均衡です。
データの不均衡を解決する必要があります。
この目標を達成するための 3 つの方法は何ですか? それぞれの正解は完全な解決策を示します。注: それぞれの正解は 1 ポイントの価値があります。
トレーニング セットは 2 つのクラス間で不均衡です。
データの不均衡を解決する必要があります。
この目標を達成するための 3 つの方法は何ですか? それぞれの正解は完全な解決策を示します。注: それぞれの正解は 1 ポイントの価値があります。
DP-100 試験問題 4
バイオメディカル研究会社は、実験的な医療治療の治験に人々を登録することを計画しています。
試験への患者の選択と参加をサポートするために、バイナリ分類モデルを作成してトレーニングします。
モデルには、年齢、性別、民族などの特徴が含まれています。
このモデルは、異なる民族グループの人々に対して異なるパフォーマンス メトリックを返します。
民族性機能の各カテゴリの格差を軽減および最小限に抑えるには、Fairlearn を使用する必要があります。
どのテクニックと制約を使用する必要がありますか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが付与されます。
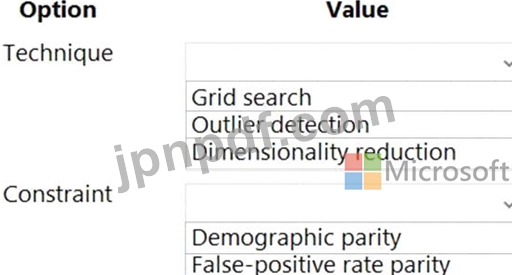
試験への患者の選択と参加をサポートするために、バイナリ分類モデルを作成してトレーニングします。
モデルには、年齢、性別、民族などの特徴が含まれています。
このモデルは、異なる民族グループの人々に対して異なるパフォーマンス メトリックを返します。
民族性機能の各カテゴリの格差を軽減および最小限に抑えるには、Fairlearn を使用する必要があります。
どのテクニックと制約を使用する必要がありますか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが付与されます。


DP-100 試験問題 5
人が病気にかかっているかどうかを予測するためのバイナリ分類モデルを作成します。
起こりうる分類エラーを検出する必要があります。
各説明に対してどのエラー タイプを選択する必要がありますか? 回答するには、回答領域で適切なオプションを選択します。
注意: 正しい選択ごとに 1 ポイントが付与されます。

起こりうる分類エラーを検出する必要があります。
各説明に対してどのエラー タイプを選択する必要がありますか? 回答するには、回答領域で適切なオプションを選択します。
注意: 正しい選択ごとに 1 ポイントが付与されます。


