
DP-100 試験問題 56
Azure Machine Learning を使用して機械学習モデルを作成します。
さまざまなコンピューティング コンテキストを使用してモデルをトレーニングし、スコアを付けることを計画しています。また、Azure Machine Learning スタジオで新しいコンピューティング リソースを作成することも計画しています。
適切なコンピューティング タイプを選択する必要があります。
どのコンピューティング タイプを選択する必要がありますか? 答えるには、適切なコンピューティング タイプを正しい要件にドラッグします。各コンピューティング タイプは、1 回だけ使用することも、複数回使用することも、まったく使用しないこともできます。コンテンツを表示するには、ペイン間で分割バーをドラッグするか、スクロールする必要がある場合があります。
注: 正しく選択するたびに 1 ポイントの価値があります。

さまざまなコンピューティング コンテキストを使用してモデルをトレーニングし、スコアを付けることを計画しています。また、Azure Machine Learning スタジオで新しいコンピューティング リソースを作成することも計画しています。
適切なコンピューティング タイプを選択する必要があります。
どのコンピューティング タイプを選択する必要がありますか? 答えるには、適切なコンピューティング タイプを正しい要件にドラッグします。各コンピューティング タイプは、1 回だけ使用することも、複数回使用することも、まったく使用しないこともできます。コンテンツを表示するには、ペイン間で分割バーをドラッグするか、スクロールする必要がある場合があります。
注: 正しく選択するたびに 1 ポイントの価値があります。

DP-100 試験問題 57
テスト要件に従ってデータを分割する方法を特定する必要があります。
どのプロパティを選択する必要がありますか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。

どのプロパティを選択する必要がありますか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。

DP-100 試験問題 58
広告レスポンスのモデリング戦略を定義する必要があります。
どの 3 つのアクションを順番に実行する必要がありますか? 回答するには、アクションのリストから適切なアクションを回答領域に移動し、正しい順序で並べます。
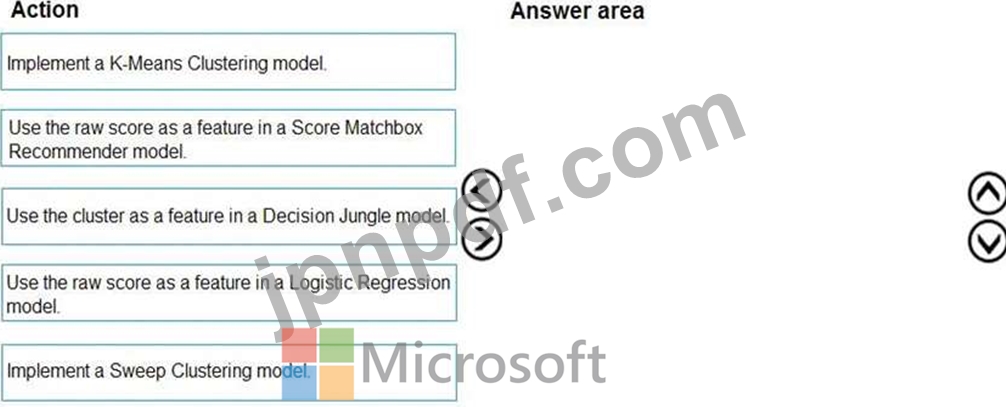
どの 3 つのアクションを順番に実行する必要がありますか? 回答するには、アクションのリストから適切なアクションを回答領域に移動し、正しい順序で並べます。
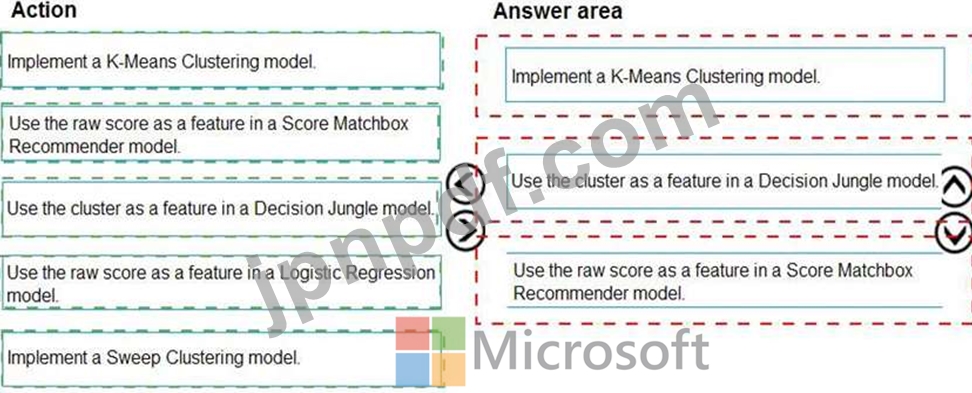

DP-100 試験問題 59
PyTorch フレームワークを使用して、マルチクラス画像分類ディープ ラーニング実験を作成します。GPU を備えたノードがある Azure コンピューティング クラスターで実験を実行する予定です。
画像分類モデルの毎月の再トレーニングを実行するには、Azure Machine Learning サービス パイプラインを定義する必要があります。パイプラインは最小限のコストで実行され、モデルのトレーニングに必要な時間を最小限に抑える必要があります。
どの 3 つのパイプライン ステップを順番に実行する必要がありますか? 回答するには、アクションのリストから適切なアクションを回答領域に移動し、正しい順序で並べます。

画像分類モデルの毎月の再トレーニングを実行するには、Azure Machine Learning サービス パイプラインを定義する必要があります。パイプラインは最小限のコストで実行され、モデルのトレーニングに必要な時間を最小限に抑える必要があります。
どの 3 つのパイプライン ステップを順番に実行する必要がありますか? 回答するには、アクションのリストから適切なアクションを回答領域に移動し、正しい順序で並べます。

DP-100 試験問題 60
あなたはチーム データ サイエンス環境を構築する予定です。機械学習パイプラインでモデルをトレーニングするためのデータのサイズは 20 GB を超えます。
次の要件があります。
* モデルは Caffe2 または Chainer フレームワークを使用して構築する必要があります。
* データ サイエンティストは、データ サイエンス環境を使用して機械学習パイプラインを構築し、接続されたネットワーク環境と切断されたネットワーク環境の両方で個人のデバイス上でモデルをトレーニングできなければなりません。
個人用デバイスは、ネットワークに接続されている場合、機械学習パイプラインの更新をサポートする必要があります。
データ サイエンス環境を選択する必要があります。
どの環境を使用する必要がありますか?
次の要件があります。
* モデルは Caffe2 または Chainer フレームワークを使用して構築する必要があります。
* データ サイエンティストは、データ サイエンス環境を使用して機械学習パイプラインを構築し、接続されたネットワーク環境と切断されたネットワーク環境の両方で個人のデバイス上でモデルをトレーニングできなければなりません。
個人用デバイスは、ネットワークに接続されている場合、機械学習パイプラインの更新をサポートする必要があります。
データ サイエンス環境を選択する必要があります。
どの環境を使用する必要がありますか?