
DP-203 試験問題 156
次の表に示すユーザーを含む Azure Synapse Analytics 専用 SQL プールがあります。
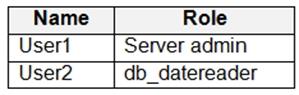
ユーザー 1 がデータベースに対してクエリを実行すると、クエリによって次の図に示す結果が返されます。

マスクされていないデータにアクセスできるのは User1 のみです。
ドロップダウン メニューを使用して、グラフィックに表示されている情報に基づいて各ステートメントを完成させる回答の選択肢を選択します。
注意: 正しい選択ごとに 1 ポイントが付与されます。

ユーザー 1 がデータベースに対してクエリを実行すると、クエリによって次の図に示す結果が返されます。
マスクされていないデータにアクセスできるのは User1 のみです。
ドロップダウン メニューを使用して、グラフィックに表示されている情報に基づいて各ステートメントを完成させる回答の選択肢を選択します。
注意: 正しい選択ごとに 1 ポイントが付与されます。

DP-203 試験問題 157
監視と管理アプリを使用して Azure データ ファクトリを監視する予定です。
ソース データベース内のテーブルを参照するアクティビティのステータスと期間を特定する必要があります。
どの 3 つのアクションを順番に実行する必要がありますか? 回答するには、アクションをアクション リストから回答に移動して、正しい順序に並べます。

ソース データベース内のテーブルを参照するアクティビティのステータスと期間を特定する必要があります。
どの 3 つのアクションを順番に実行する必要がありますか? 回答するには、アクションをアクション リストから回答に移動して、正しい順序に並べます。


DP-203 試験問題 158
注: この質問は、同じシナリオを提示する一連の質問の一部です。一連の質問にはそれぞれ、定められた目標を満たす独自の解決策が含まれています。質問セットによっては、正しい解決策が複数ある場合もあれば、正しい解決策がない場合もあります。
このセクションで質問に答えた後は、そのセクションに戻ることはできません。そのため、これらの質問はレビュー画面に表示されません。
階層構造を持つ Azure Databricks ワークスペースを作成する予定です。ワークスペースには、次の 3 つのワークロードが含まれます。
* Python と SQL を使用するデータ エンジニア向けのワークロード。
* Python、Scala、SOL を使用するノートブックを実行するジョブのワークロード。
* データ サイエンティストが Scala と R でアドホック分析を実行するために使用するワークロード。
会社のエンタープライズ アーキテクチャ チームは、Databricks 環境に対して次の標準を特定します。
* データ エンジニアはクラスターを共有する必要があります。
* ジョブ クラスターは、データ サイエンティストとデータ エンジニアがクラスターにデプロイするためのパッケージ化されたノートブックを提供するリクエスト プロセスを使用して管理されます。
* すべてのデータ サイエンティストに独自のクラスターを割り当てる必要があります。クラスターは、120 分間操作がないと自動的に終了します。現在、データ サイエンティストは 3 人います。
ワークロード用の Databricks クラスターを作成する必要があります。
解決策: 各データ サイエンティスト用に高同時実行クラスターを作成し、データ エンジニア用に高同時実行クラスターを作成し、ジョブ用に標準クラスターを作成します。
これは目標を満たしていますか?
このセクションで質問に答えた後は、そのセクションに戻ることはできません。そのため、これらの質問はレビュー画面に表示されません。
階層構造を持つ Azure Databricks ワークスペースを作成する予定です。ワークスペースには、次の 3 つのワークロードが含まれます。
* Python と SQL を使用するデータ エンジニア向けのワークロード。
* Python、Scala、SOL を使用するノートブックを実行するジョブのワークロード。
* データ サイエンティストが Scala と R でアドホック分析を実行するために使用するワークロード。
会社のエンタープライズ アーキテクチャ チームは、Databricks 環境に対して次の標準を特定します。
* データ エンジニアはクラスターを共有する必要があります。
* ジョブ クラスターは、データ サイエンティストとデータ エンジニアがクラスターにデプロイするためのパッケージ化されたノートブックを提供するリクエスト プロセスを使用して管理されます。
* すべてのデータ サイエンティストに独自のクラスターを割り当てる必要があります。クラスターは、120 分間操作がないと自動的に終了します。現在、データ サイエンティストは 3 人います。
ワークロード用の Databricks クラスターを作成する必要があります。
解決策: 各データ サイエンティスト用に高同時実行クラスターを作成し、データ エンジニア用に高同時実行クラスターを作成し、ジョブ用に標準クラスターを作成します。
これは目標を満たしていますか?
DP-203 試験問題 159
インターネットに接続されたリモート センサーからのストリーミング データを視覚化するリアルタイム ダッシュボード ソリューションを設計しています。ストリーミング データは、10 秒間隔ごとの平均値を表示するために集計する必要があります。データはダッシュボードに表示された後、破棄されます。
このソリューションは Azure Stream Analytics を使用し、次の要件を満たす必要があります。
* Azure イベント ハブからダッシュボードまでの待機時間を最小限に抑えます。
* 必要なストレージを最小限に抑えます。
* 開発の労力を最小限に抑えます。
解決策には何を含めるべきですか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正解を選ぶごとに1ポイント獲得できます

このソリューションは Azure Stream Analytics を使用し、次の要件を満たす必要があります。
* Azure イベント ハブからダッシュボードまでの待機時間を最小限に抑えます。
* 必要なストレージを最小限に抑えます。
* 開発の労力を最小限に抑えます。
解決策には何を含めるべきですか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正解を選ぶごとに1ポイント獲得できます


DP-203 試験問題 160
Azure Databricks の PySpark を使用して、次の JSON 入力を解析します。

次の表形式でデータを出力する必要があります。
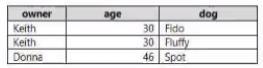
PySpark コードをどのように完成させるべきでしょうか? 回答するには、適切な値を正しいターゲットにドラッグします。
各値は 1 回、複数回、またはまったく使用されない場合があります。コンテンツを表示するには、ペイン間の分割バーをドラッグするか、スクロールする必要がある場合があります。
注意: 正しい選択ごとに 1 ポイントが付与されます。

次の表形式でデータを出力する必要があります。
PySpark コードをどのように完成させるべきでしょうか? 回答するには、適切な値を正しいターゲットにドラッグします。
各値は 1 回、複数回、またはまったく使用されない場合があります。コンテンツを表示するには、ペイン間の分割バーをドラッグするか、スクロールする必要がある場合があります。
注意: 正しい選択ごとに 1 ポイントが付与されます。

