
DP-203 試験問題 146
Apache Spark DataFrame にtemperaturesという名前が付いています。データのサンプルを次の表に示します。
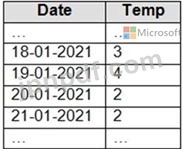
Spark SQL クエリを使用して次のテーブルを作成する必要があります。

クエリを完了するにはどうすればよいでしょうか。回答するには、適切な値を正しいターゲットにドラッグします。各値は、1 回、複数回、またはまったく使用されない場合があります。コンテンツを表示するには、ペイン間の分割バーをドラッグするか、スクロールする必要がある場合があります。
注意: 正しい選択ごとに 1 ポイントが付与されます。

Spark SQL クエリを使用して次のテーブルを作成する必要があります。
クエリを完了するにはどうすればよいでしょうか。回答するには、適切な値を正しいターゲットにドラッグします。各値は、1 回、複数回、またはまったく使用されない場合があります。コンテンツを表示するには、ペイン間の分割バーをドラッグするか、スクロールする必要がある場合があります。
注意: 正しい選択ごとに 1 ポイントが付与されます。

DP-203 試験問題 147
Job1 という名前の Azure Stream Analytics ジョブがあります。
過去 1 時間の Job1 のメトリックを次の表に示します。
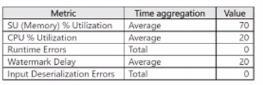
Job1 の遅延許容値は 5 秒に設定されています。
Job1 を最適化する必要があります。
どの 2 つのアクションが目標を達成しますか? それぞれの正解は完全な解決策を示します。
注意: 正解ごとに 1 ポイントが付与されます。
過去 1 時間の Job1 のメトリックを次の表に示します。
Job1 の遅延許容値は 5 秒に設定されています。
Job1 を最適化する必要があります。
どの 2 つのアクションが目標を達成しますか? それぞれの正解は完全な解決策を示します。
注意: 正解ごとに 1 ポイントが付与されます。
DP-203 試験問題 148
Azure Data Factory パイプラインを構築して、Azure Data Lake Storage Gen2 コンテナーから Azure Synapse Analytics 専用 SQL プール内のデータベースにデータを移動します。
コンテナ内のデータは、次のフォルダ構造に保存されます。
/in/{YYYY}/{MM}/{DD}/{HH}/{mm}
最も古いフォルダーは /in/2021/01/01/00/00 です。最新のフォルダーは /in/2021/01/15/01/45 です。
次の要件を満たすようにパイプライン トリガーを構成する必要があります。
既存のデータをロードする必要があります。
データは30分ごとにロードする必要があります。
最大 2 分遅れて到着するデータは、データが到着するはずだった時間のロードに含める必要があります。
パイプライン トリガーをどのように構成すればよいですか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが付与されます。

コンテナ内のデータは、次のフォルダ構造に保存されます。
/in/{YYYY}/{MM}/{DD}/{HH}/{mm}
最も古いフォルダーは /in/2021/01/01/00/00 です。最新のフォルダーは /in/2021/01/15/01/45 です。
次の要件を満たすようにパイプライン トリガーを構成する必要があります。
既存のデータをロードする必要があります。
データは30分ごとにロードする必要があります。
最大 2 分遅れて到着するデータは、データが到着するはずだった時間のロードに含める必要があります。
パイプライン トリガーをどのように構成すればよいですか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが付与されます。

DP-203 試験問題 149
毎日 200,000 個の新しいファイルを生成する Azure ストレージ アカウントがあります。ファイル名の形式は (YYY)/(MM)/(DD)/|HH])/(CustornerID).csv です。
ストレージ アカウントから Azure Data Lake に 1 時間ごとに新しいデータをアップロードする Azure Data Factory ソリューションを設計する必要があります。ソリューションでは、読み込み時間とコストを最小限に抑える必要があります。
ソリューションをどのように構成すればよいですか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが付与されます。
ストレージ アカウントから Azure Data Lake に 1 時間ごとに新しいデータをアップロードする Azure Data Factory ソリューションを設計する必要があります。ソリューションでは、読み込み時間とコストを最小限に抑える必要があります。
ソリューションをどのように構成すればよいですか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが付与されます。

DP-203 試験問題 150
Azure Data Lake Storage アカウントを含む Azure サブスクリプションがあります。ストレージ アカウントには、DataLake1 という名前のデータ レイクが含まれています。
Azure データ ファクトリを使用して、DataLake1 のフォルダーからデータを取り込み、データを変換して、別のフォルダーに配置する予定です。
データ ファクトリが DataLake1 ファイル システム内の任意のフォルダーからデータを読み書きできることを確認する必要があります。
ソリューションは次の要件を満たす必要があります。
不正なユーザーアクセスのリスクを最小限に抑えます。
最小権限の原則を使用します。
メンテナンスの労力を最小限に抑えます。
データ ファクトリのストレージ アカウントへのアクセスをどのように構成すればよいですか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが付与されます。

Azure データ ファクトリを使用して、DataLake1 のフォルダーからデータを取り込み、データを変換して、別のフォルダーに配置する予定です。
データ ファクトリが DataLake1 ファイル システム内の任意のフォルダーからデータを読み書きできることを確認する必要があります。
ソリューションは次の要件を満たす必要があります。
不正なユーザーアクセスのリスクを最小限に抑えます。
最小権限の原則を使用します。
メンテナンスの労力を最小限に抑えます。
データ ファクトリのストレージ アカウントへのアクセスをどのように構成すればよいですか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが付与されます。

