
DP-203 試験問題 301
Azure Data Lake Storage Gen2 アカウントへのアクセスを提供するのはお客様の責任です。
ユーザー アカウントにはストレージ アカウントへの共同作成者アクセス権があり、アプリケーション ID とアクセス キーを持っています。
PolyBase を使用して、Azure Synapse Analytics のエンタープライズ データ ウェアハウスにデータを読み込むことを計画しています。
データ ウェアハウスをストレージ アカウントに接続するには、PolyBase を構成する必要があります。
どの 3 つのコンポーネントを順番に作成する必要がありますか? 回答するには、コンポーネントのリストから適切なコンポーネントを回答領域に移動し、正しい順序で配置します。
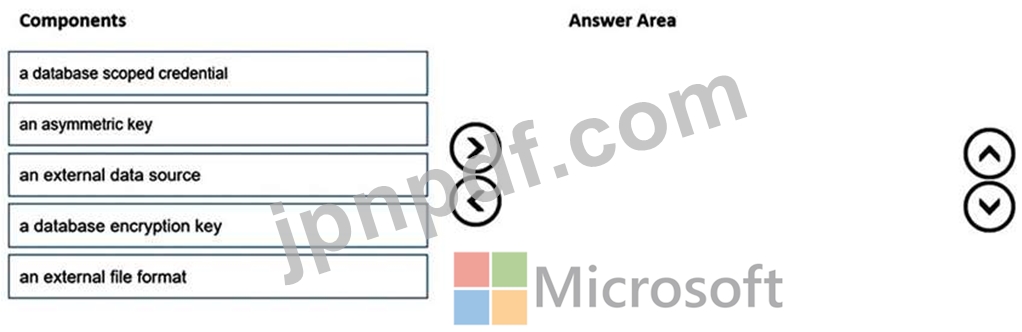
ユーザー アカウントにはストレージ アカウントへの共同作成者アクセス権があり、アプリケーション ID とアクセス キーを持っています。
PolyBase を使用して、Azure Synapse Analytics のエンタープライズ データ ウェアハウスにデータを読み込むことを計画しています。
データ ウェアハウスをストレージ アカウントに接続するには、PolyBase を構成する必要があります。
どの 3 つのコンポーネントを順番に作成する必要がありますか? 回答するには、コンポーネントのリストから適切なコンポーネントを回答領域に移動し、正しい順序で配置します。


DP-203 試験問題 302
あなたは、Azure Event Hubs から受信したデータを処理し、Azure Data Lake Storage Gen2 コンテナーに取り込むための Azure Data Factory ソリューションを構築しています。
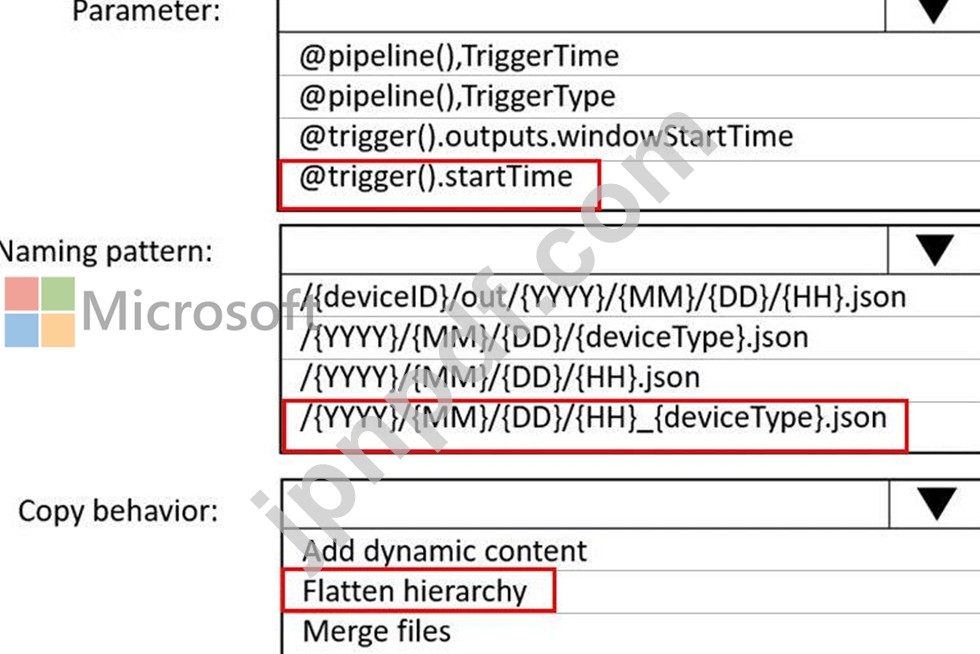
データは 5 分ごとにデバイスから JSON ファイルに取り込まれます。ファイルには次の命名パターンがあります。
/{deviceType}/in/{YYYY}/{MM}/{DD}/{HH}/{deviceID}_{YYYY}{MM}{DD}HH}{mm}.json のデータを準備する必要がありますバッチ データ処理により、deviceType ごとに 1 時間に 1 つのデータセットが作成されます。ソリューションでは読み取り時間を最小限に抑える必要があります。
コピー アクティビティ用にシンクをどのように構成すればよいでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。
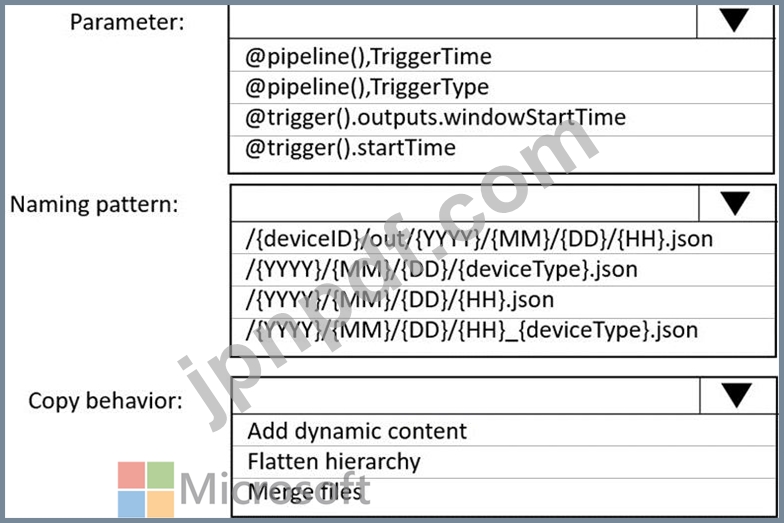
データは 5 分ごとにデバイスから JSON ファイルに取り込まれます。ファイルには次の命名パターンがあります。
/{deviceType}/in/{YYYY}/{MM}/{DD}/{HH}/{deviceID}_{YYYY}{MM}{DD}HH}{mm}.json のデータを準備する必要がありますバッチ データ処理により、deviceType ごとに 1 時間に 1 つのデータセットが作成されます。ソリューションでは読み取り時間を最小限に抑える必要があります。
コピー アクティビティ用にシンクをどのように構成すればよいでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。
DP-203 試験問題 303
Azure Synapse Analytics にエンタープライズ データ ウェアハウスがあります。
PolyBase を使用して、[Ext].[Items] という名前の外部テーブルを作成し、データをデータ ウェアハウスにインポートせずに、Azure Data Lake Storage Gen2 に格納されている Parquet ファイルをクエリします。
外部テーブルには 3 つの列があります。
Parquet ファイルには、ItemID という名前の 4 番目の列があることがわかります。
ItemID 列を外部テーブルに追加するには、どのコマンドを実行する必要がありますか?
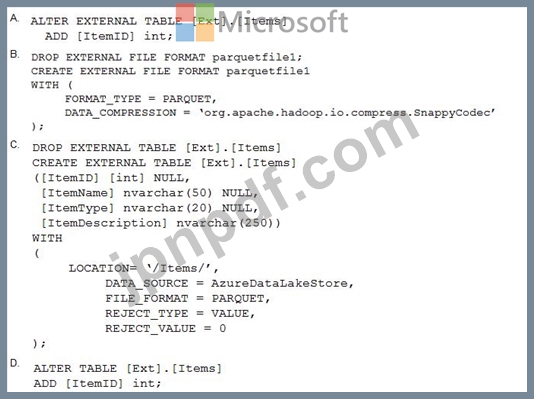
PolyBase を使用して、[Ext].[Items] という名前の外部テーブルを作成し、データをデータ ウェアハウスにインポートせずに、Azure Data Lake Storage Gen2 に格納されている Parquet ファイルをクエリします。
外部テーブルには 3 つの列があります。
Parquet ファイルには、ItemID という名前の 4 番目の列があることがわかります。
ItemID 列を外部テーブルに追加するには、どのコマンドを実行する必要がありますか?
DP-203 試験問題 304
workspace1 という名前の Azure Synapse Analytics ワークスペースを含む Azure サブスクリプションがあります。
Workspace1 には、SQL Pool という名前の専用 SQL プールと、sparkpool という名前の Apache Spark プールが含まれています。
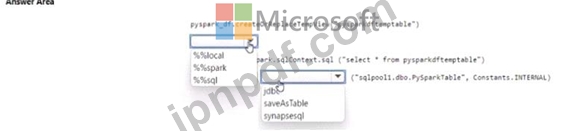
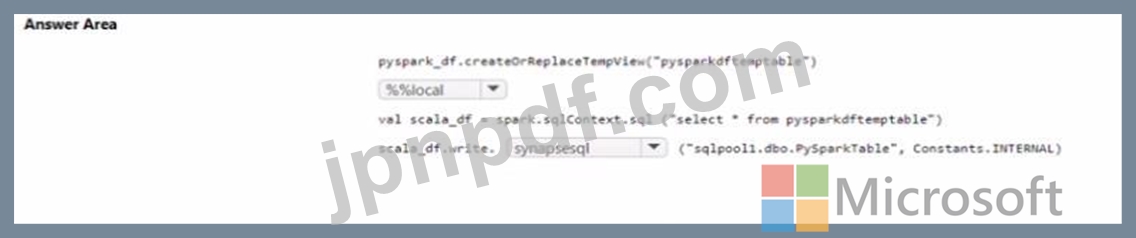
Sparkpool1 には、pyspark.df という名前のデータフレームが含まれています。
PySpark ノートブックを使用して、pyspark_df の内容を SQLPooM のタブテに書き込む必要があります。
コードをどのように完成させるべきでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。
Workspace1 には、SQL Pool という名前の専用 SQL プールと、sparkpool という名前の Apache Spark プールが含まれています。
Sparkpool1 には、pyspark.df という名前のデータフレームが含まれています。
PySpark ノートブックを使用して、pyspark_df の内容を SQLPooM のタブテに書き込む必要があります。
コードをどのように完成させるべきでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。

DP-203 試験問題 305
Azure Synapse Analytics 専用の SQL プールを設計しています。
次の表に示すように、グループはプール内の機密データにアクセスできます。

機密データに対するポリシーがある
a.次の表に示すように、ポリシーは地域によって異なります。

各地域の患者のテーブルがあります。テーブルには、次のような機密性の高い列が含まれています。

あなたは、コンプライアンスを維持するために動的データ マスキングを設計しています。
次の各ステートメントについて、そのステートメントが true の場合は [はい] を選択します。それ以外の場合は、「いいえ」を選択します。
注: 正しく選択するたびに 1 ポイントの価値があります。

次の表に示すように、グループはプール内の機密データにアクセスできます。
機密データに対するポリシーがある
a.次の表に示すように、ポリシーは地域によって異なります。
各地域の患者のテーブルがあります。テーブルには、次のような機密性の高い列が含まれています。
あなたは、コンプライアンスを維持するために動的データ マスキングを設計しています。
次の各ステートメントについて、そのステートメントが true の場合は [はい] を選択します。それ以外の場合は、「いいえ」を選択します。
注: 正しく選択するたびに 1 ポイントの価値があります。
