DP-203 試験問題 266
Azure Data Factory パイプラインを構築して、Azure Data Lake Storage Gen2 コンテナーから Azure Synapse Analytics 専用 SQL プール内のデータベースにデータを移動します。
コンテナ内のデータは以下のフォルダ構成で格納されます。
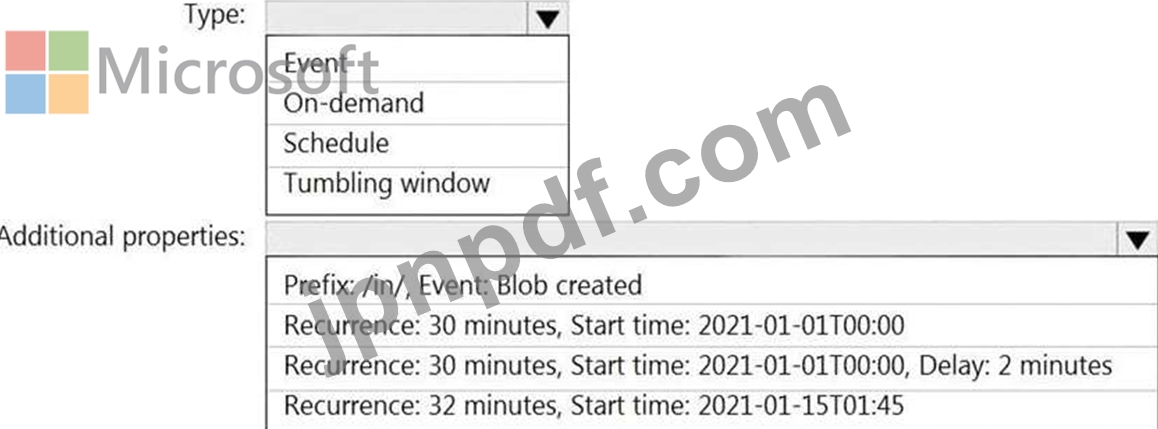
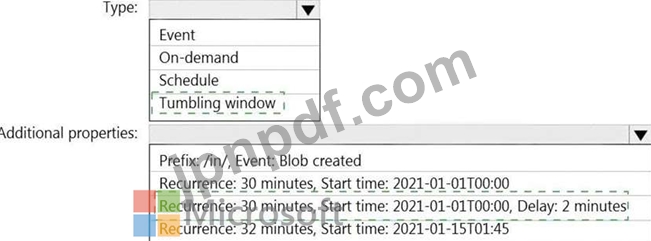
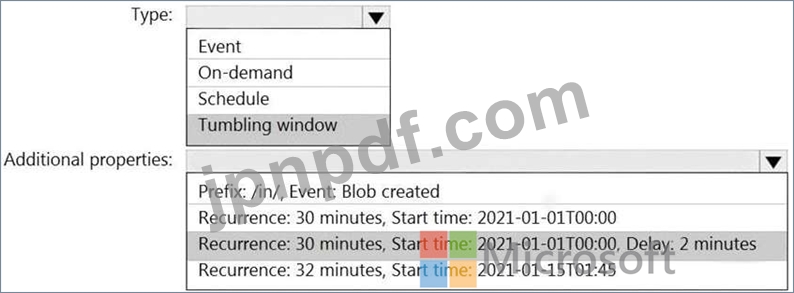
/in/{YYYY}/{MM}/{DD}/{HH}/{mm}
最も古いフォルダーは /in/2021/01/01/00/00 です。最新のフォルダーは/in/2021/01/15/01/45です。
次の要件を満たすようにパイプライン トリガーを構成する必要があります。
※既存のデータを読み込む必要があります。
※30分ごとにデータをロードする必要があります。
* 最大 2 分間の遅延到着データは、データが到着するはずだった時刻の負荷に含める必要があります。
パイプライン トリガーをどのように構成すればよいでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。
コンテナ内のデータは以下のフォルダ構成で格納されます。
/in/{YYYY}/{MM}/{DD}/{HH}/{mm}
最も古いフォルダーは /in/2021/01/01/00/00 です。最新のフォルダーは/in/2021/01/15/01/45です。
次の要件を満たすようにパイプライン トリガーを構成する必要があります。
※既存のデータを読み込む必要があります。
※30分ごとにデータをロードする必要があります。
* 最大 2 分間の遅延到着データは、データが到着するはずだった時刻の負荷に含める必要があります。
パイプライン トリガーをどのように構成すればよいでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。
DP-203 試験問題 267
製品カタログ ファイルから参照データをクエリする Azure Stream Analytics ジョブを構築しています。ファイルは毎日更新されます。
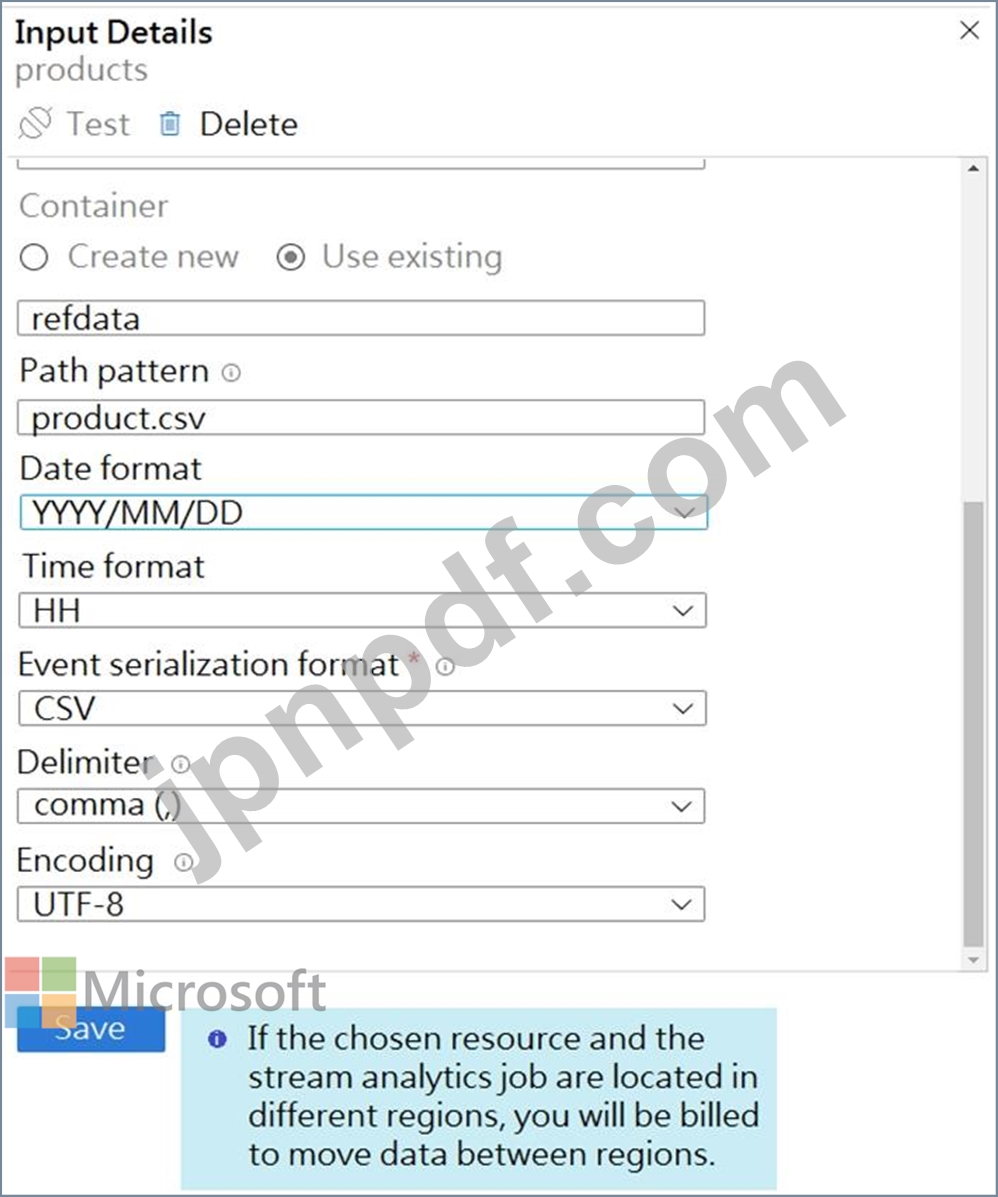
ファイルの参照データ入力の詳細は、「入力」セクションに表示されます。(「入力」タブをクリックします。)
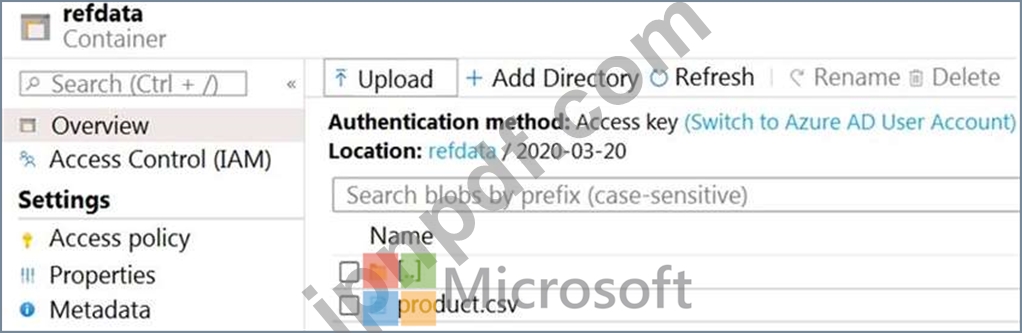
ストレージ アカウント コンテナー ビューは、Refdata の展示に示されています。(「参照データ」タブをクリックします。)
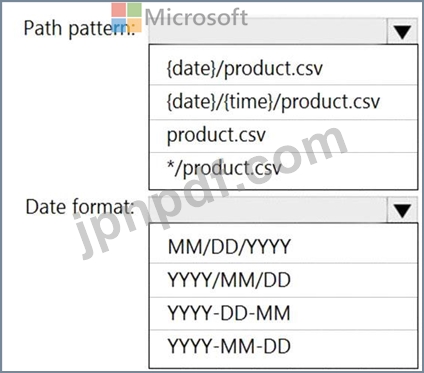
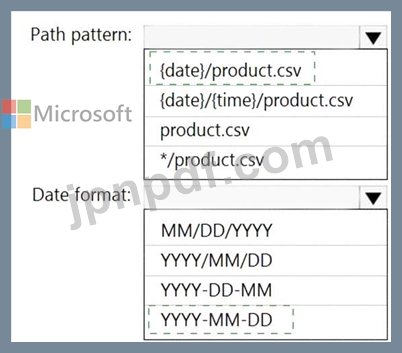
新しい参照データを取得するには、Stream Analytics ジョブを構成する必要があります。
何を設定すればよいでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。
ファイルの参照データ入力の詳細は、「入力」セクションに表示されます。(「入力」タブをクリックします。)
ストレージ アカウント コンテナー ビューは、Refdata の展示に示されています。(「参照データ」タブをクリックします。)
新しい参照データを取得するには、Stream Analytics ジョブを構成する必要があります。
何を設定すればよいでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。
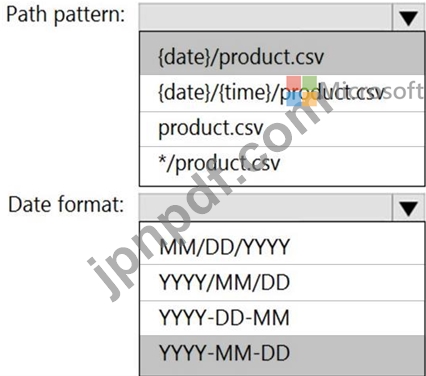
DP-203 試験問題 268
Microsoft Purview アカウントに接続する Azure データ ファクトリがあります。データ ファクトリは Microsoft Purview に登録されます。
Data Factory パイプラインを更新します。
更新されたリネージが Microsoft Purview で利用可能であることを確認する必要があります。
DB1 という名前の Azure SQL データベースと storage1 という名前のストレージ アカウントを含む Azure サブスクリプションを持っています。storage1 アカウントには、File1.txt という名前のファイルが含まれています。File1.txt には、DB1 で選択したテーブルの名前が含まれています。
DB1 内の選択したテーブルから storage1 内のファイルにデータをコピーするには、Azure Synapse パイプラインを使用する必要があります。ソリューションは次の要件を満たす必要があります。
* パイプラインのコピー アクティビティは、File1.txt 内のデータを使用してコピーのソースと宛先を識別するようにパラメーター化する必要があります。
* コピー アクティビティは、できるだけ頻繁に並行して実行する必要があります。
パイプラインに含める必要がある 2 つのパイプライン アクティビティはどれですか? それぞれの正解は、解決策の一部を示しています。注: 正しく選択するたびに 1 ポイントの価値があります。
Data Factory パイプラインを更新します。
更新されたリネージが Microsoft Purview で利用可能であることを確認する必要があります。
DB1 という名前の Azure SQL データベースと storage1 という名前のストレージ アカウントを含む Azure サブスクリプションを持っています。storage1 アカウントには、File1.txt という名前のファイルが含まれています。File1.txt には、DB1 で選択したテーブルの名前が含まれています。
DB1 内の選択したテーブルから storage1 内のファイルにデータをコピーするには、Azure Synapse パイプラインを使用する必要があります。ソリューションは次の要件を満たす必要があります。
* パイプラインのコピー アクティビティは、File1.txt 内のデータを使用してコピーのソースと宛先を識別するようにパラメーター化する必要があります。
* コピー アクティビティは、できるだけ頻繁に並行して実行する必要があります。
パイプラインに含める必要がある 2 つのパイプライン アクティビティはどれですか? それぞれの正解は、解決策の一部を示しています。注: 正しく選択するたびに 1 ポイントの価値があります。
DP-203 試験問題 269
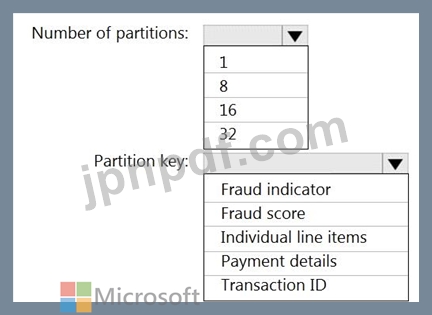
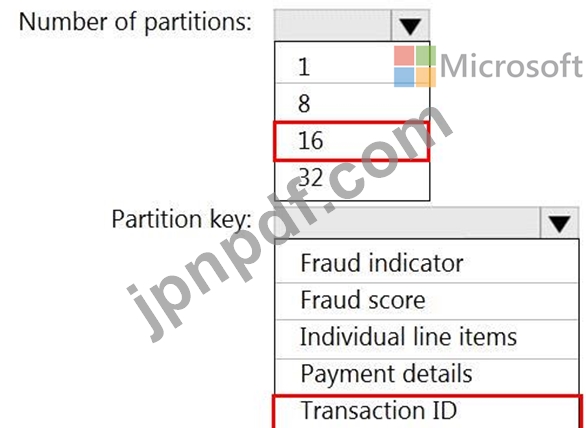
16 個のパーティションを持つ、retailhub という名前の Azure イベント ハブがあります。トランザクションはretailhubに投稿されます。各トランザクションには、トランザクション ID、個々の品目、および支払いの詳細が含まれます。トランザクション ID はパーティション キーとして使用されます。
あなたは、小売店での不正の可能性のある取引を特定するための Azure Stream Analytics ジョブを設計しています。このジョブは、retailhub を入力として使用します。このジョブは、トランザクション ID、個々の品目、支払詳細、不正スコア、および不正インジケータを出力します。
出力を、fraudhub という名前の Azure イベント ハブに送信する予定です。
不正検出ソリューションが拡張性が高く、トランザクションをできるだけ早く処理することを確認する必要があります。
Stream Analytics ジョブの出力をどのように構成すればよいでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。
あなたは、小売店での不正の可能性のある取引を特定するための Azure Stream Analytics ジョブを設計しています。このジョブは、retailhub を入力として使用します。このジョブは、トランザクション ID、個々の品目、支払詳細、不正スコア、および不正インジケータを出力します。
出力を、fraudhub という名前の Azure イベント ハブに送信する予定です。
不正検出ソリューションが拡張性が高く、トランザクションをできるだけ早く処理することを確認する必要があります。
Stream Analytics ジョブの出力をどのように構成すればよいでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。
DP-203 試験問題 270
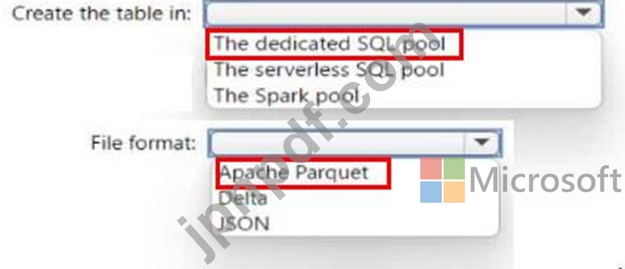
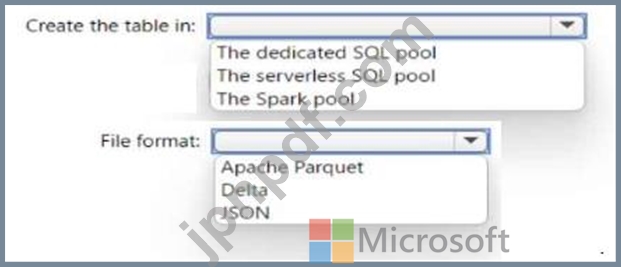
Azure Synapse Analytics サーバーレス SQL プール、Azure Synapse Analytics 専用 SQL プール、Apache Spark プール、および Azure Data Lake Storage Gen2 アカウントがある。
Lake データベースにテーブルを作成する必要があります。テーブルはサーバーレス SQL プールと Spark プールの両方で使用できる必要があります。
テーブルをどこに作成する必要がありますか?また、テーブル内のデータにはどのファイル形式を使用する必要がありますか? 回答するには、回答内の適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。
Lake データベースにテーブルを作成する必要があります。テーブルはサーバーレス SQL プールと Spark プールの両方で使用できる必要があります。
テーブルをどこに作成する必要がありますか?また、テーブル内のデータにはどのファイル形式を使用する必要がありますか? 回答するには、回答内の適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。