
DP-203 試験問題 226
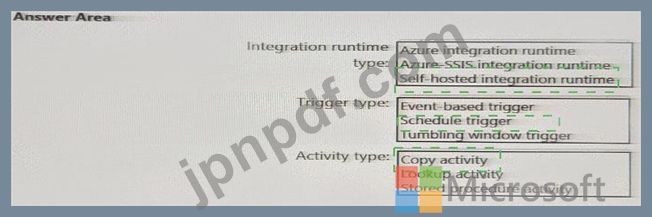
毎日のインベントリ データを SQL サーバーから Azure Data Lake Storage にインポートするには、どの Azure Data Factory コンポーネントを併用することをお勧めしますか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。
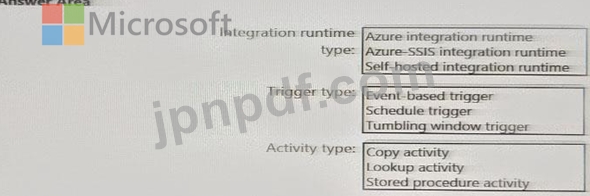
注: 正しく選択するたびに 1 ポイントの価値があります。
DP-203 試験問題 227
次の Azure Stream Analytics クエリがあります。
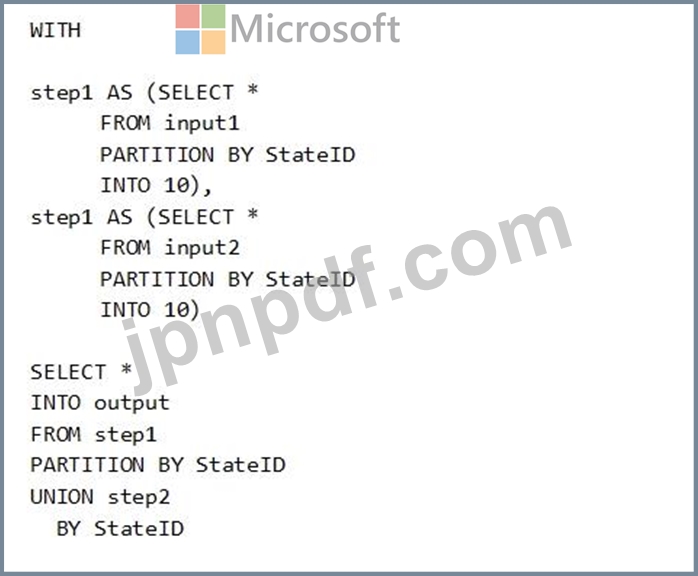
次の各ステートメントについて、そのステートメントが true の場合は [はい] を選択します。それ以外の場合は、「いいえ」を選択します。
注: 正しく選択するたびに 1 ポイントの価値があります。

次の各ステートメントについて、そのステートメントが true の場合は [はい] を選択します。それ以外の場合は、「いいえ」を選択します。
注: 正しく選択するたびに 1 ポイントの価値があります。


DP-203 試験問題 228
次の図に示すアクティビティを持つ Azure Data Factory パイプラインがあります。

ドロップダウン メニューを使用して、図に示されている情報に基づいて各ステートメントを完成させる回答の選択肢を選択します。

ドロップダウン メニューを使用して、図に示されている情報に基づいて各ステートメントを完成させる回答の選択肢を選択します。

DP-203 試験問題 229
Trigger1 という名前のタンブリング ウィンドウ トリガーによって呼び出される、pipeline1 という名前の Azure Data Factory パイプラインがあります。Trigger1 の繰り返しは 60 分です。
前回の実行が正常に完了した場合にのみ Pipeline1 が実行されるようにする必要があります。
Trigger1 の自己依存性をどのように構成すればよいでしょうか?
前回の実行が正常に完了した場合にのみ Pipeline1 が実行されるようにする必要があります。
Trigger1 の自己依存性をどのように構成すればよいでしょうか?
DP-203 試験問題 230
注: この質問は、同じシナリオを示す一連の質問の一部です。このシリーズの各質問には、指定された目標を達成できる可能性のある独自の解決策が含まれています。一部の質問セットには複数の正しい解決策が含まれる場合がありますが、他の質問セットには正しい解決策がない場合があります。
このセクションの質問に回答すると、その質問に戻ることはできません。そのため、これらの質問はレビュー画面には表示されません。
階層構造を持つ Azure Databricks ワークスペースを作成する予定です。ワークスペースには次の 3 つのワークロードが含まれます。
* Python と SQL を使用するデータ エンジニア向けのワークロード。
* Python、Scala、SOL を使用するノートブックを実行するジョブのワークロード。
* データ サイエンティストが Scala および R でアドホック分析を実行するために使用するワークロード。
あなたの会社のエンタープライズ アーキテクチャ チームは、Databricks 環境の次の標準を特定します。
* データ エンジニアはクラスターを共有する必要があります。
* ジョブ クラスターは、データ サイエンティストとデータ エンジニアがクラスターに展開するためのパッケージ化されたノートブックを提供するリクエスト プロセスを使用して管理されます。
* すべてのデータ サイエンティストには、120 分間非アクティブ状態が続くと自動的に終了する独自のクラスターを割り当てる必要があります。現在、データサイエンティストは3名います。
ワークロード用の Databricks クラスターを作成する必要があります。
解決策: 各データ サイエンティスト用に高同時実行クラスターを作成し、データ エンジニア用に高同時実行クラスターを作成し、ジョブ用に標準クラスターを作成します。
これは目標を達成していますか?
このセクションの質問に回答すると、その質問に戻ることはできません。そのため、これらの質問はレビュー画面には表示されません。
階層構造を持つ Azure Databricks ワークスペースを作成する予定です。ワークスペースには次の 3 つのワークロードが含まれます。
* Python と SQL を使用するデータ エンジニア向けのワークロード。
* Python、Scala、SOL を使用するノートブックを実行するジョブのワークロード。
* データ サイエンティストが Scala および R でアドホック分析を実行するために使用するワークロード。
あなたの会社のエンタープライズ アーキテクチャ チームは、Databricks 環境の次の標準を特定します。
* データ エンジニアはクラスターを共有する必要があります。
* ジョブ クラスターは、データ サイエンティストとデータ エンジニアがクラスターに展開するためのパッケージ化されたノートブックを提供するリクエスト プロセスを使用して管理されます。
* すべてのデータ サイエンティストには、120 分間非アクティブ状態が続くと自動的に終了する独自のクラスターを割り当てる必要があります。現在、データサイエンティストは3名います。
ワークロード用の Databricks クラスターを作成する必要があります。
解決策: 各データ サイエンティスト用に高同時実行クラスターを作成し、データ エンジニア用に高同時実行クラスターを作成し、ジョブ用に標準クラスターを作成します。
これは目標を達成していますか?