DP-203 試験問題 6
Azure Databricks を使用して、DBTBL1 という名前のデータセットを開発します。
DBTBL1 には次の列が含まれます。
センサータイプID
地理地域ID
年
月
日
時間
分
温度
風速
他の
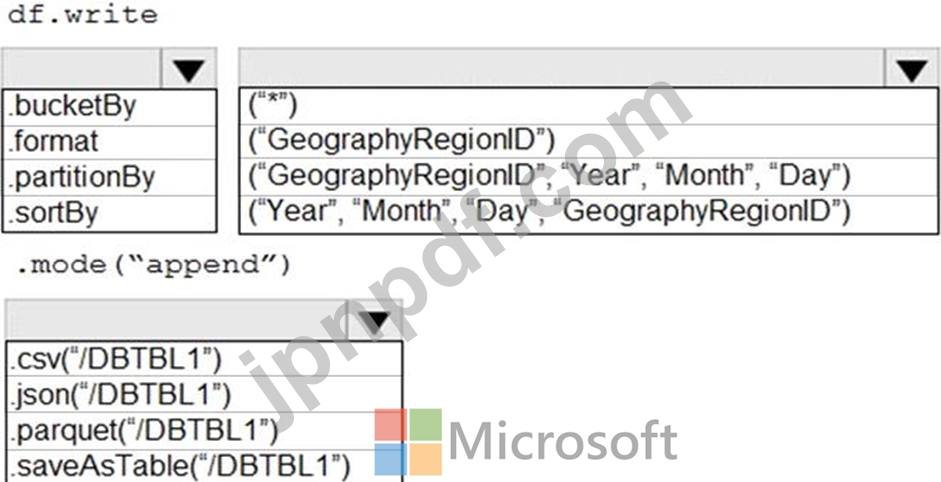
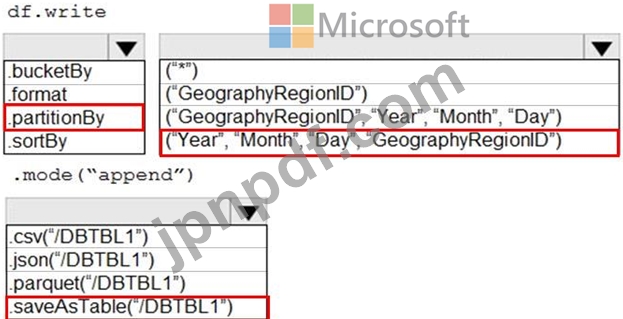
GeographyRegionID ごとに異なる毎日の増分読み込みパイプラインをサポートするには、データを保存する必要があります。ソリューションでは、ストレージ コストを最小限に抑える必要があります。
コードをどのように完成させるべきでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。
DBTBL1 には次の列が含まれます。
センサータイプID
地理地域ID
年
月
日
時間
分
温度
風速
他の
GeographyRegionID ごとに異なる毎日の増分読み込みパイプラインをサポートするには、データを保存する必要があります。ソリューションでは、ストレージ コストを最小限に抑える必要があります。
コードをどのように完成させるべきでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。
DP-203 試験問題 7
Azure Data Factory を使用して、Azure Synapse Analytics サーバーレス SQL プールによってクエリされるデータを準備します。
ファイルは最初、10 個の小さな JSON ファイルとして Azure Data Lake Storage Gen2 アカウントに取り込まれます。各ファイルには、同じデータ属性と会社の子会社からのデータが含まれています。
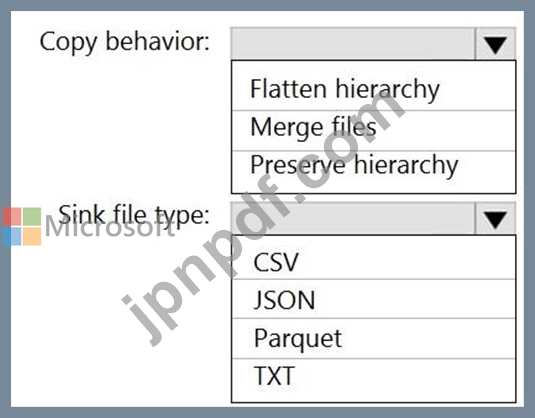
ファイルを別のフォルダーに移動し、次の要件を満たすようにデータを変換する必要があります。
可能な限り最速のクエリ時間を提供します。
基礎となるファイルからスキーマを自動的に推測します。
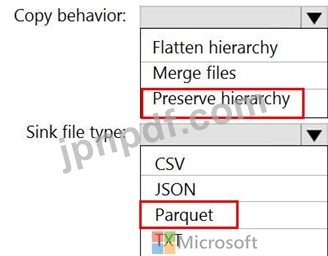
Data Factory のコピー アクティビティをどのように構成すればよいですか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。
ファイルは最初、10 個の小さな JSON ファイルとして Azure Data Lake Storage Gen2 アカウントに取り込まれます。各ファイルには、同じデータ属性と会社の子会社からのデータが含まれています。
ファイルを別のフォルダーに移動し、次の要件を満たすようにデータを変換する必要があります。
可能な限り最速のクエリ時間を提供します。
基礎となるファイルからスキーマを自動的に推測します。
Data Factory のコピー アクティビティをどのように構成すればよいですか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。
DP-203 試験問題 8
統合パイプラインにバージョン管理された変更を実装する必要があります。ソリューションはデータ統合要件を満たしている必要があります。
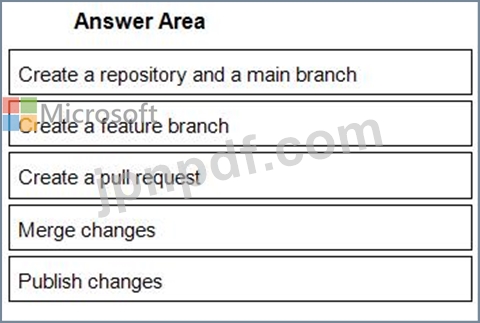
どの順序でアクションを実行する必要がありますか? 回答するには、すべてのアクションをアクションのリストから回答領域に移動し、正しい順序で並べます。

どの順序でアクションを実行する必要がありますか? 回答するには、すべてのアクションをアクションのリストから回答領域に移動し、正しい順序で並べます。
DP-203 試験問題 9
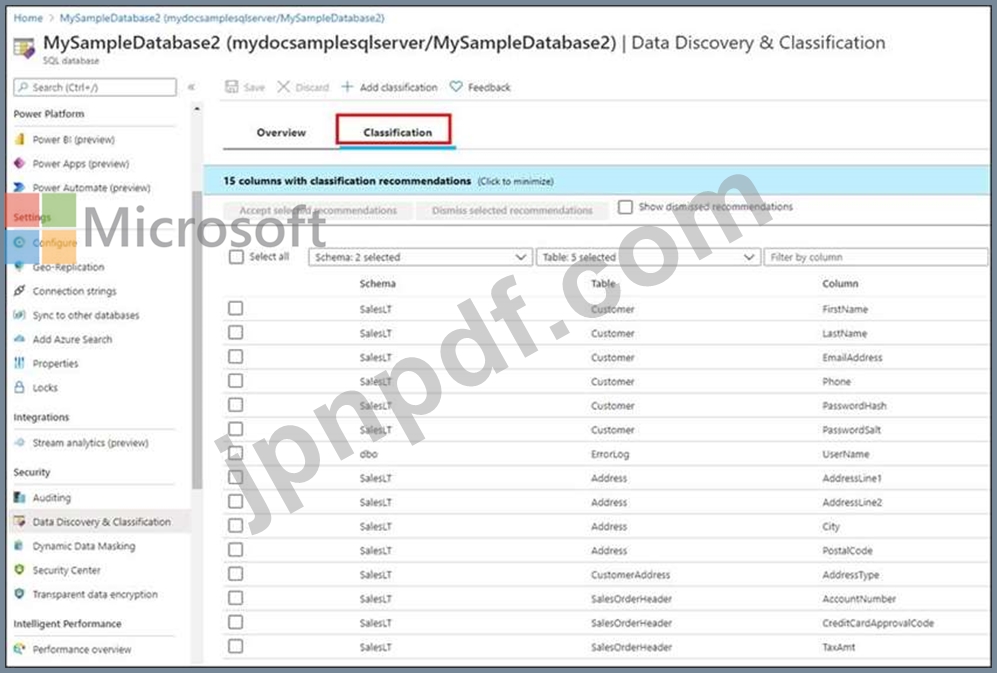
機密性の高い顧客の連絡先情報を保護するには、何を使用することをお勧めしますか?
DP-203 試験問題 10
Azure Synapse Analytics 専用の SQL プールを作成する予定です。
会社のデータ プライバシー規制で定義されている機密情報を返すクエリと、キューを実行したユーザーを特定するのにかかる時間を最小限に抑える必要があります。
ソリューションに含めるべき 2 つのコンポーネントはどれですか? それぞれの正解は、解決策の一部を示しています。
注: 正しく選択するたびに 1 ポイントの価値があります。
会社のデータ プライバシー規制で定義されている機密情報を返すクエリと、キューを実行したユーザーを特定するのにかかる時間を最小限に抑える必要があります。
ソリューションに含めるべき 2 つのコンポーネントはどれですか? それぞれの正解は、解決策の一部を示しています。
注: 正しく選択するたびに 1 ポイントの価値があります。