
DP-203 試験問題 36
Table1 という名前のテーブルを含む SA1 という名前の Azure Synapse Analytics 専用 SQL プールがあります。
削除された行の割合が高いテーブルを特定する必要があります。何を実行すればよいでしょうか?
削除された行の割合が高いテーブルを特定する必要があります。何を実行すればよいでしょうか?
DP-203 試験問題 37
Azure Synapse Analytics 専用 SQL プール内のファクト テーブルにデータを段階的に読み込んでいます。
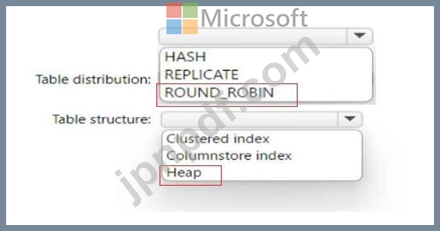
受信データの各バッチは、ファクト テーブルにロードされる前にステージングされます。| 受信データができるだけ早くステージングされるようにする必要があります。| ステージング テーブルをどのように構成すればよいでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
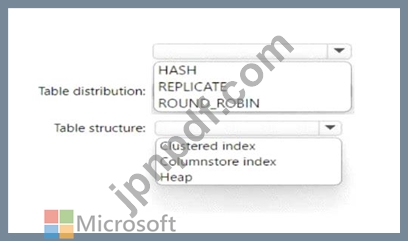
受信データの各バッチは、ファクト テーブルにロードされる前にステージングされます。| 受信データができるだけ早くステージングされるようにする必要があります。| ステージング テーブルをどのように構成すればよいでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
DP-203 試験問題 38
注: この質問は、同じシナリオを示す一連の質問の一部です。このシリーズの各質問には、指定された目標を達成できる可能性のある独自の解決策が含まれています。一部の質問セットには複数の正しい解決策が含まれる場合がありますが、他の質問セットには正しい解決策がない場合があります。
このセクションの質問に回答すると、その質問に戻ることはできません。そのため、これらの質問はレビュー画面には表示されません。
階層構造を持つ Azure Databricks ワークスペースを作成する予定です。ワークスペースには次の 3 つのワークロードが含まれます。
Python と SQL を使用するデータ エンジニア向けのワークロード。
Python、Scala、SOL を使用するノートブックを実行するジョブのワークロード。
データ サイエンティストが Scala および R でアドホック分析を実行するために使用するワークロード。
あなたの会社のエンタープライズ アーキテクチャ チームは、Databricks 環境の次の標準を特定します。
データ エンジニアはクラスターを共有する必要があります。
ジョブ クラスターは、データ サイエンティストとデータ エンジニアがクラスターに展開するためのパッケージ化されたノートブックを提供するリクエスト プロセスを使用して管理されます。
すべてのデータ サイエンティストには、非アクティブ状態が 120 分間続くと自動的に終了する独自のクラスターを割り当てる必要があります。現在、データサイエンティストは3名います。
ワークロード用の Databricks クラスターを作成する必要があります。
解決策: 各データ サイエンティスト用に標準クラスターを作成し、データ エンジニア用に標準クラスターを作成し、ジョブ用に高同時実行クラスターを作成します。
これは目標を達成していますか?
このセクションの質問に回答すると、その質問に戻ることはできません。そのため、これらの質問はレビュー画面には表示されません。
階層構造を持つ Azure Databricks ワークスペースを作成する予定です。ワークスペースには次の 3 つのワークロードが含まれます。
Python と SQL を使用するデータ エンジニア向けのワークロード。
Python、Scala、SOL を使用するノートブックを実行するジョブのワークロード。
データ サイエンティストが Scala および R でアドホック分析を実行するために使用するワークロード。
あなたの会社のエンタープライズ アーキテクチャ チームは、Databricks 環境の次の標準を特定します。
データ エンジニアはクラスターを共有する必要があります。
ジョブ クラスターは、データ サイエンティストとデータ エンジニアがクラスターに展開するためのパッケージ化されたノートブックを提供するリクエスト プロセスを使用して管理されます。
すべてのデータ サイエンティストには、非アクティブ状態が 120 分間続くと自動的に終了する独自のクラスターを割り当てる必要があります。現在、データサイエンティストは3名います。
ワークロード用の Databricks クラスターを作成する必要があります。
解決策: 各データ サイエンティスト用に標準クラスターを作成し、データ エンジニア用に標準クラスターを作成し、ジョブ用に高同時実行クラスターを作成します。
これは目標を達成していますか?
DP-203 試験問題 39
Contacts という名前のテーブルを含む Azure Synapse Analytics 専用の SQL プールがあります。「連絡先」には「電話」という名前の列が含まれています。
電話列をクエリする場合、特定のロールのユーザーに電話番号の最後の 4 桁のみが表示されるようにする必要があります。
ソリューションには何を含めるべきでしょうか?
電話列をクエリする場合、特定のロールのユーザーに電話番号の最後の 4 桁のみが表示されるようにする必要があります。
ソリューションには何を含めるべきでしょうか?
DP-203 試験問題 40
ADFdev と ADFprod という名前の 2 つの Azure Data Factory インスタンスがあります。ADFdev は Azure DevOps Git リポジトリに接続します。
変更を Git リポジトリのメイン ブランチから ADFdev に公開します。
アーティファクトをADFdevからADFprodにデプロイする必要があります。
まず何をすべきでしょうか?
変更を Git リポジトリのメイン ブランチから ADFdev に公開します。
アーティファクトをADFdevからADFprodにデプロイする必要があります。
まず何をすべきでしょうか?