
DP-203 試験問題 181
寄木細工の形式でバッチデータセットを実装しています。
データタイルは、Azure Data Factoryを使用して作成され、Azure Data LakeStorageGen2に保存されます。ファイルは、AzureSynapseAnalyticsサーバーレスSQLプールによって消費されます。
ソリューションのストレージコストを最小限に抑える必要があります。
あなたは何をするべきか?
データタイルは、Azure Data Factoryを使用して作成され、Azure Data LakeStorageGen2に保存されます。ファイルは、AzureSynapseAnalyticsサーバーレスSQLプールによって消費されます。
ソリューションのストレージコストを最小限に抑える必要があります。
あなたは何をするべきか?
DP-203 試験問題 182
AzureSynapseAnalytics専用のSQLプールを設計しています。
次の表に示すように、グループはプール内の機密データにアクセスできます。

機密データのポリシーがあります
a。次の表に示すように、ポリシーは地域によって異なります。

各地域の患者の表があります。表には、次の潜在的に機密性の高い列が含まれています。

コンプライアンスを維持するために動的データマスキングを設計しています。
次の各ステートメントについて、ステートメントがtrueの場合は、[はい]を選択します。それ以外の場合は、[いいえ]を選択します。
注:正しい選択はそれぞれ1ポイントの価値があります。

次の表に示すように、グループはプール内の機密データにアクセスできます。
機密データのポリシーがあります
a。次の表に示すように、ポリシーは地域によって異なります。
各地域の患者の表があります。表には、次の潜在的に機密性の高い列が含まれています。
コンプライアンスを維持するために動的データマスキングを設計しています。
次の各ステートメントについて、ステートメントがtrueの場合は、[はい]を選択します。それ以外の場合は、[いいえ]を選択します。
注:正しい選択はそれぞれ1ポイントの価値があります。

DP-203 試験問題 183
統合パイプラインにバージョン管理された変更を実装する必要があります。ソリューションは、データ統合要件を満たす必要があります。
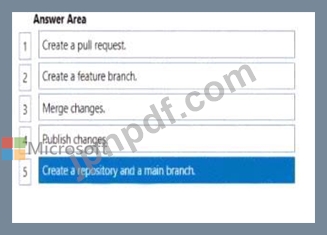
アクションを実行する順序はどれですか。回答するには、すべてのアクションをアクションのリストから回答領域に移動し、正しい順序に並べます。

アクションを実行する順序はどれですか。回答するには、すべてのアクションをアクションのリストから回答領域に移動し、正しい順序に並べます。

DP-203 試験問題 184
Webサイト分析システムから、ダウンロード、リンククリック、フォーム送信、ビデオ再生などのユーザーインタラクションに関するデータ抽出を受け取ります。
データには次の列が含まれています。
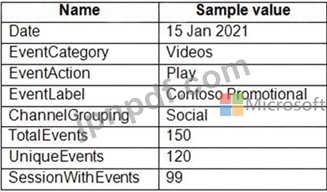
データの分析クエリをサポートするスタースキーマを設計する必要があります。スタースキーマには、日付ディメンションを含む4つのテーブルが含まれます。
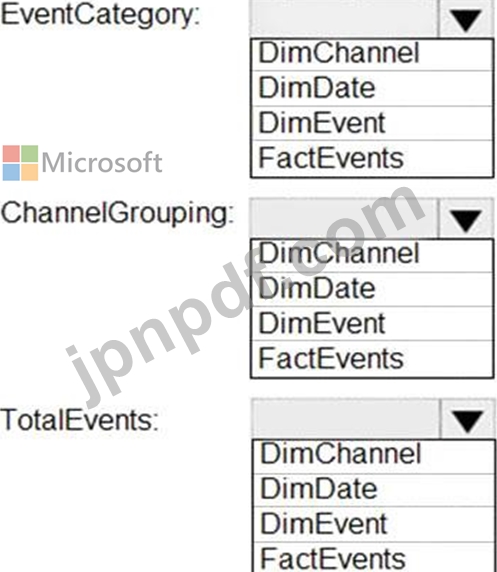
各列をどのテーブルに追加する必要がありますか?回答するには、回答エリアで適切なオプションを選択してください。
注:正しい選択はそれぞれ1ポイントの価値があります。
データには次の列が含まれています。
データの分析クエリをサポートするスタースキーマを設計する必要があります。スタースキーマには、日付ディメンションを含む4つのテーブルが含まれます。
各列をどのテーブルに追加する必要がありますか?回答するには、回答エリアで適切なオプションを選択してください。
注:正しい選択はそれぞれ1ポイントの価値があります。


DP-203 試験問題 185
mytestdbという名前のApacheSparkデータベースを含むMyWorkspaceという名前のAzureSynapseワークスペースがあります。
MyWorkspaceのAzureSynapseAnalyticsSparkプールで次のコマンドを実行します。
CREATE TABLE mytestdb.myParquetTable(
EmployeeID int、
EmployeeName文字列、
EmployeeStartDate日付)
寄木細工の使用
次に、Sparkを使用してmytestdb.myParquetTableに行を挿入します。行には次のデータが含まれています。

1分後、MyWorkspaceのサーバーレスSQLプールから次のクエリを実行します。
SELECT EmployeeID
mytestdb.dbo.myParquetTableから
WHERE name='アリス';
クエリによって何が返されますか?
MyWorkspaceのAzureSynapseAnalyticsSparkプールで次のコマンドを実行します。
CREATE TABLE mytestdb.myParquetTable(
EmployeeID int、
EmployeeName文字列、
EmployeeStartDate日付)
寄木細工の使用
次に、Sparkを使用してmytestdb.myParquetTableに行を挿入します。行には次のデータが含まれています。
1分後、MyWorkspaceのサーバーレスSQLプールから次のクエリを実行します。
SELECT EmployeeID
mytestdb.dbo.myParquetTableから
WHERE name='アリス';
クエリによって何が返されますか?