
DP-100 試験問題 86
バイオメディカル研究会社は、実験的な医療治療の治験に人々を登録することを計画しています。
試験への患者の選択と参加をサポートするために、バイナリ分類モデルを作成してトレーニングします。モデルには、年齢、性別、民族などの特徴が含まれます。
このモデルは、異なる民族グループの人々に対して異なるパフォーマンス メトリックを返します。
民族性機能の各カテゴリの格差を軽減および最小限に抑えるには、Fairlearn を使用する必要があります。
どのテクニックと制約を使用する必要がありますか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが付与されます。

試験への患者の選択と参加をサポートするために、バイナリ分類モデルを作成してトレーニングします。モデルには、年齢、性別、民族などの特徴が含まれます。
このモデルは、異なる民族グループの人々に対して異なるパフォーマンス メトリックを返します。
民族性機能の各カテゴリの格差を軽減および最小限に抑えるには、Fairlearn を使用する必要があります。
どのテクニックと制約を使用する必要がありますか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが付与されます。

DP-100 試験問題 87
AccessibilityToHighway 列の欠落データを置き換える必要があります。
欠落データのクリーンアップ モジュールをどのように構成すればよいですか? 回答するには、回答領域で適切なオプションを選択します。
注意: 正しい選択ごとに 1 ポイントが付与されます。

欠落データのクリーンアップ モジュールをどのように構成すればよいですか? 回答するには、回答領域で適切なオプションを選択します。
注意: 正しい選択ごとに 1 ポイントが付与されます。


DP-100 試験問題 88
統計分布の非対称性を分析しています。
次の画像には、2 つのデータセットの確率分布を示す 2 つの密度曲線が含まれています。
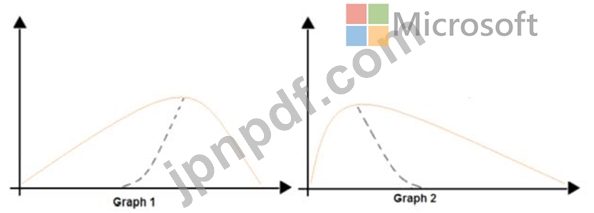
ドロップダウン メニューを使用して、グラフィックに表示されている情報に基づいて各質問に答える選択肢を選択します。
注意: 正しい選択ごとに 1 ポイントが付与されます。

次の画像には、2 つのデータセットの確率分布を示す 2 つの密度曲線が含まれています。
ドロップダウン メニューを使用して、グラフィックに表示されている情報に基づいて各質問に答える選択肢を選択します。
注意: 正しい選択ごとに 1 ポイントが付与されます。
DP-100 試験問題 89
Azure Machine Learning Service を使用して、ニューラル ネットワーク分類モデルのハイパーパラメータ探索を自動化しています。
次の要件に従ってランダム サンプリングを使用してハイパーパラメータを自動的に調整するには、ハイパーパラメータ空間を定義する必要があります。
学習率は、平均値 10、標準偏差 3 の正規分布から選択する必要があります。
バッチ サイズは 16、32、64 にする必要があります。
保持確率は、0.05 ~ 0.1 の範囲の均一分布から選択された値である必要があります。
Azure Machine Learning Service には、Python API の param_sampling メソッドを使用する必要があります。
コード セグメントをどのように完了する必要がありますか? 回答するには、回答領域で適切なオプションを選択します。
注意: 正しい選択ごとに 1 ポイントが付与されます。

次の要件に従ってランダム サンプリングを使用してハイパーパラメータを自動的に調整するには、ハイパーパラメータ空間を定義する必要があります。
学習率は、平均値 10、標準偏差 3 の正規分布から選択する必要があります。
バッチ サイズは 16、32、64 にする必要があります。
保持確率は、0.05 ~ 0.1 の範囲の均一分布から選択された値である必要があります。
Azure Machine Learning Service には、Python API の param_sampling メソッドを使用する必要があります。
コード セグメントをどのように完了する必要がありますか? 回答するには、回答領域で適切なオプションを選択します。
注意: 正しい選択ごとに 1 ポイントが付与されます。

DP-100 試験問題 90
Azure Machine Learning Studio で実験を作成し、10,000 行を含むトレーニング データセットを追加します。最初の 9,000 行はクラス 0 (90%) を表します。最初の 1,000 行はクラス 1 (10%) を表します。
トレーニング セットは 2 つのクラス間で不均衡です。データ行を使用して、クラス 1 のトレーニング例の数を 4,000 に増やす必要があります。実験に Synthetic Minority Oversampling Technique (SMOTE) モジュールを追加します。
モジュールを設定する必要があります。
どの値を使用すればよいですか? 回答するには、回答領域のダイアログ ボックスで適切なオプションを選択します。
注意: 正しい選択ごとに 1 ポイントが付与されます。

トレーニング セットは 2 つのクラス間で不均衡です。データ行を使用して、クラス 1 のトレーニング例の数を 4,000 に増やす必要があります。実験に Synthetic Minority Oversampling Technique (SMOTE) モジュールを追加します。
モジュールを設定する必要があります。
どの値を使用すればよいですか? 回答するには、回答領域のダイアログ ボックスで適切なオプションを選択します。
注意: 正しい選択ごとに 1 ポイントが付与されます。
