
DP-100 試験問題 101
Azure Machine Learning SDK を使用して、分類モデルをトレーニングし、その精度メトリックを計算するトレーニング実験を実行します。
新しいデータが利用可能になると、モデルは毎月再トレーニングされます。
バッチ推論パイプラインで使用するにはモデルを登録する必要があります。
モデルを登録し、その後の再トレーニング実験で作成されたモデルが、現在登録されているモデルよりも精度が高い場合にのみ登録されるようにする必要があります。
この目標を達成するために考えられる 2 つの方法は何ですか? それぞれの正解は完全な解決策を示します。
注: 正しく選択するたびに 1 ポイントの価値があります。
新しいデータが利用可能になると、モデルは毎月再トレーニングされます。
バッチ推論パイプラインで使用するにはモデルを登録する必要があります。
モデルを登録し、その後の再トレーニング実験で作成されたモデルが、現在登録されているモデルよりも精度が高い場合にのみ登録されるようにする必要があります。
この目標を達成するために考えられる 2 つの方法は何ですか? それぞれの正解は完全な解決策を示します。
注: 正しく選択するたびに 1 ポイントの価値があります。
DP-100 試験問題 102
Azure Machine Learning を使用して、モデルをリアルタイム Web サービスとしてデプロイします。
サービスの開始時にモデルがロードされ、受信時に新しいデータのスコアリングに使用されるようにするサービスのエントリ スクリプトを作成する必要があります。
どの関数をスクリプトに含めるべきでしょうか? 答えるには、適切な関数を正しいアクションにドラッグします。各関数は 1 回使用することも、複数回使用することも、まったく使用しないこともできます。コンテンツを表示するには、ペイン間で分割バーをドラッグするか、スクロールする必要がある場合があります。 注: 正しく選択するたびに 1 ポイントの価値があります。

サービスの開始時にモデルがロードされ、受信時に新しいデータのスコアリングに使用されるようにするサービスのエントリ スクリプトを作成する必要があります。
どの関数をスクリプトに含めるべきでしょうか? 答えるには、適切な関数を正しいアクションにドラッグします。各関数は 1 回使用することも、複数回使用することも、まったく使用しないこともできます。コンテンツを表示するには、ペイン間で分割バーをドラッグするか、スクロールする必要がある場合があります。 注: 正しく選択するたびに 1 ポイントの価値があります。


DP-100 試験問題 103
Azure Machine Learning サービスを使用して、training.dat a という名前の表形式のデータセットを作成します。このデータセットをトレーニング スクリプトで使用する予定です。
次のコードを使用して、データセットを参照する変数を作成します。
training_ds = workspace.datasets.get("training_data")
スクリプトを実行するためのエスティメーターを定義します。
スクリプトが training.data データセットにアクセスできるようにするには、推定器の正しいプロパティを設定する必要があります。どのプロパティを設定する必要がありますか?
次のコードを使用して、データセットを参照する変数を作成します。
training_ds = workspace.datasets.get("training_data")
スクリプトを実行するためのエスティメーターを定義します。
スクリプトが training.data データセットにアクセスできるようにするには、推定器の正しいプロパティを設定する必要があります。どのプロパティを設定する必要がありますか?
DP-100 試験問題 104
2,000 行を含むデータセットがあります。Azure Machine Learning Studio を使用して、機械学習分類モデルを構築します。パーティションとサンプル モジュールを実験に追加します。
モジュールを構成する必要があります。次の要件を満たす必要があります。
* データをサブセットに分割します。
* ラウンドロビン方式を使用して行をフォールドに割り当てます。
* データセット内の行を再利用できるようにします。
モジュールをどのように構成すればよいでしょうか? 回答するには、回答領域のダイアログ ボックスで適切なオプションを選択します。
注: 正しく選択するたびに 1 ポイントの価値があります。


モジュールを構成する必要があります。次の要件を満たす必要があります。
* データをサブセットに分割します。
* ラウンドロビン方式を使用して行をフォールドに割り当てます。
* データセット内の行を再利用できるようにします。
モジュールをどのように構成すればよいでしょうか? 回答するには、回答領域のダイアログ ボックスで適切なオプションを選択します。
注: 正しく選択するたびに 1 ポイントの価値があります。

DP-100 試験問題 105
C サポート ベクトル分類を使用して、不均衡なトレーニング データセットでマルチクラス分類を実行しています。Python コードを使用した C サポート ベクターの分類を以下に示します。
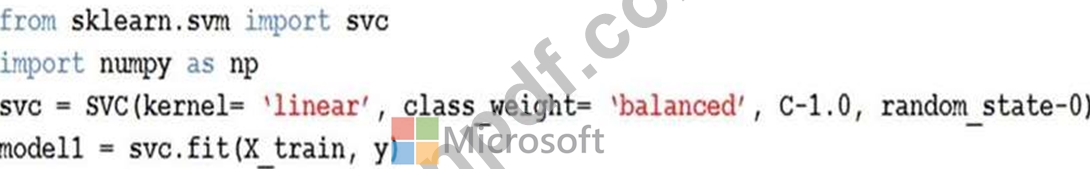
C-Support Vector 分類コードを評価する必要があります。
どの評価ステートメントを使用する必要がありますか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。
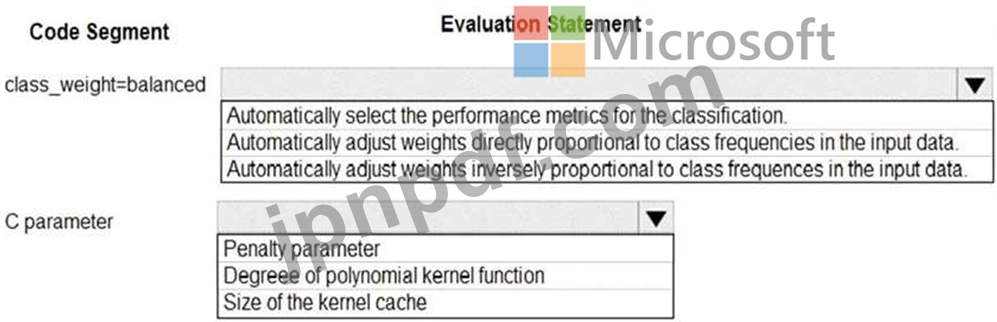
C-Support Vector 分類コードを評価する必要があります。
どの評価ステートメントを使用する必要がありますか? 回答するには、回答領域で適切なオプションを選択してください。
注: 正しく選択するたびに 1 ポイントの価値があります。

