
DP-100 試験問題 171
Azure Machine Learning Studioを使用してマルチクラス分類子を構築するために、データセットに対してフィルターベースの特徴選択を実行しています。
データセットには、出力ラベル列と高度に相関するカテゴリ機能が含まれています。
主要な予測因子を特定するには、適切な特徴スコアリング統計手法を選択する必要があります。
どの方法を使用する必要がありますか?
データセットには、出力ラベル列と高度に相関するカテゴリ機能が含まれています。
主要な予測因子を特定するには、適切な特徴スコアリング統計手法を選択する必要があります。
どの方法を使用する必要がありますか?
DP-100 試験問題 172
注:この質問は、同じシナリオを提示する一連の質問の一部です。シリーズの各質問には、述べられた目標を達成する可能性のある独自の解決策が含まれています。一部の質問セットには複数の正しい解決策がある場合がありますが、他の質問セットには正しい解決策がない場合があります。
このセクションの質問に回答した後は、その質問に戻ることはできません。その結果、これらの質問はレビュー画面に表示されません。
履歴データに基づいて気象条件を予測するモデルを作成します。
処理スクリプトを実行してデータストアからデータを読み込み、処理されたデータを機械学習モデルのトレーニングスクリプトに渡すパイプラインを作成する必要があります。
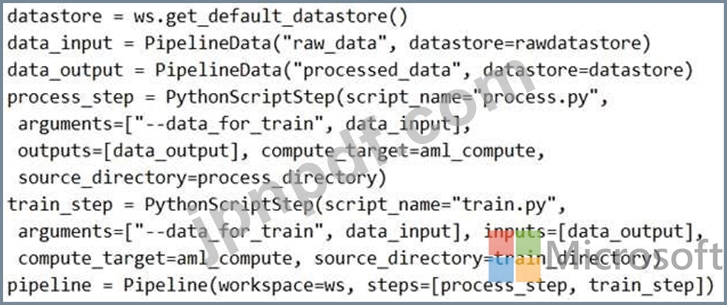
解決策:次のコードを実行します。
ソリューションは目標を達成していますか?
このセクションの質問に回答した後は、その質問に戻ることはできません。その結果、これらの質問はレビュー画面に表示されません。
履歴データに基づいて気象条件を予測するモデルを作成します。
処理スクリプトを実行してデータストアからデータを読み込み、処理されたデータを機械学習モデルのトレーニングスクリプトに渡すパイプラインを作成する必要があります。
解決策:次のコードを実行します。
ソリューションは目標を達成していますか?
DP-100 試験問題 173
二項分類を実行するためにリカレントニューラルネットワークを構築しています。
各トレーニングエポックのトレーニング損失、検証損失、トレーニング精度、および検証精度が提供されています。分類モデルが過剰に適合しているかどうかを識別する必要があります。
次のうち正しいものはどれですか?
各トレーニングエポックのトレーニング損失、検証損失、トレーニング精度、および検証精度が提供されています。分類モデルが過剰に適合しているかどうかを識別する必要があります。
次のうち正しいものはどれですか?
DP-100 試験問題 174
統計分布で非対称性を分析しています。
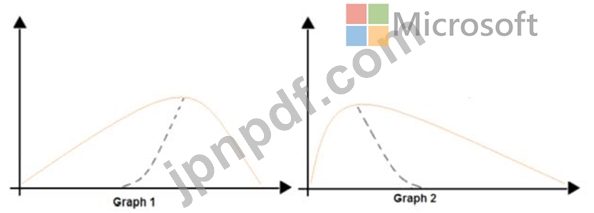
次の画像には、2つのデータセットの確率分布を示す2つの密度曲線が含まれています。
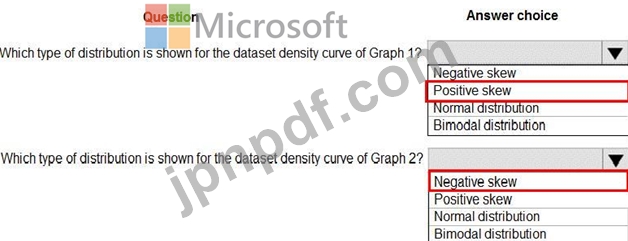
ドロップダウンメニューを使用して、図に示されている情報に基づいて各質問に回答する回答の選択肢を選択します。
注:正しい選択はそれぞれ1ポイントの価値があります。

次の画像には、2つのデータセットの確率分布を示す2つの密度曲線が含まれています。
ドロップダウンメニューを使用して、図に示されている情報に基づいて各質問に回答する回答の選択肢を選択します。
注:正しい選択はそれぞれ1ポイントの価値があります。
DP-100 試験問題 175
注:この質問は、同じシナリオを提示する一連の質問の一部です。シリーズの各質問には、述べられた目標を達成する可能性のある独自の解決策が含まれています。一部の質問セットには複数の正しい解決策がある場合がありますが、他の質問セットには正しい解決策がない場合があります。
このセクションの質問に回答した後は、その質問に戻ることはできません。その結果、これらの質問はレビュー画面に表示されません。
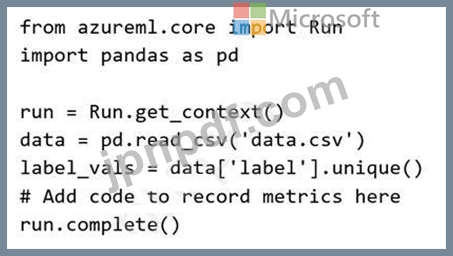
Pythonスクリプトを使用して、AzureMachineLearningの実験を実行することを計画しています。スクリプトは、実験実行コンテキストへの参照を作成し、ファイルからデータをロードし、ラベル列の一意の値のセットを識別して、実験実行を完了します。
実験では、後で確認できる実行のメトリックとして、データに一意のラベルを記録する必要があります。
コメントで示されたポイントで実行メトリックとして一意のラベル値を記録するには、スクリプトにコードを追加する必要があります。
解決策:コメントを次のコードに置き換えます。
run.log_list('ラベル値'、label_vals)
ソリューションは目標を達成していますか?
このセクションの質問に回答した後は、その質問に戻ることはできません。その結果、これらの質問はレビュー画面に表示されません。
Pythonスクリプトを使用して、AzureMachineLearningの実験を実行することを計画しています。スクリプトは、実験実行コンテキストへの参照を作成し、ファイルからデータをロードし、ラベル列の一意の値のセットを識別して、実験実行を完了します。
実験では、後で確認できる実行のメトリックとして、データに一意のラベルを記録する必要があります。
コメントで示されたポイントで実行メトリックとして一意のラベル値を記録するには、スクリプトにコードを追加する必要があります。
解決策:コメントを次のコードに置き換えます。
run.log_list('ラベル値'、label_vals)
ソリューションは目標を達成していますか?