
DP-300 試験問題 1
Azure SQL マネージド インスタンス、db1 という名前のデータベース、および Appl という名前の Azure Web アプリを含む Azure サブスクリプションがあります。Appl は db1 を使用します。
App1 のリソース ガバナーを有効にする必要があります。ソリューションは次の要件を満たしている必要があります。
App1 は利用可能なすべての CPU リソースを消費できる必要があります。
App1 では、使用可能な CPU リソースの少なくとも半分が常に使用可能である必要があります。
どの 3 つのアクションを順番に実行する必要がありますか? 回答するには、アクションのリストから適切なアクションを回答領域に移動し、正しい順序で並べます。注: 回答の選択肢の順序は複数あっても正しい場合があります。正しい順序を選択した場合は、そのどれでもポイントが付与されます。

App1 のリソース ガバナーを有効にする必要があります。ソリューションは次の要件を満たしている必要があります。
App1 は利用可能なすべての CPU リソースを消費できる必要があります。
App1 では、使用可能な CPU リソースの少なくとも半分が常に使用可能である必要があります。
どの 3 つのアクションを順番に実行する必要がありますか? 回答するには、アクションのリストから適切なアクションを回答領域に移動し、正しい順序で並べます。注: 回答の選択肢の順序は複数あっても正しい場合があります。正しい順序を選択した場合は、そのどれでもポイントが付与されます。

DP-300 試験問題 2
次の Transact-SQL クエリがあります。
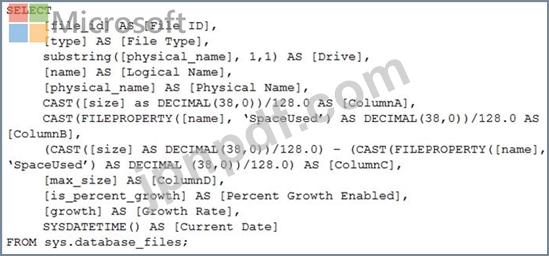
クエリによって返されるどの列が各ファイルの空き領域を表しますか?
クエリによって返されるどの列が各ファイルの空き領域を表しますか?
DP-300 試験問題 3
注: この質問は、同じシナリオを提示する一連の質問の一部です。一連の質問にはそれぞれ、定められた目標を満たす独自の解決策が含まれています。質問セットによっては、正しい解決策が複数ある場合もあれば、正しい解決策がない場合もあります。
このセクションで質問に答えた後は、そのセクションに戻ることはできません。そのため、これらの質問はレビュー画面に表示されません。
ステージング ゾーンを含む Azure Data Lake Storage アカウントがあります。
ステージング ゾーンから増分データを取り込み、R スクリプトを実行してデータを変換し、変換されたデータを Azure Synapse Analytics のデータ ウェアハウスに挿入する毎日のプロセスを設計する必要があります。
解決策: Azure Data Factory スケジュール トリガーを使用して、マッピング データ フローを実行するパイプラインを実行し、データをデータ ウェアハウスに挿入します。
これは目標を満たしていますか?
このセクションで質問に答えた後は、そのセクションに戻ることはできません。そのため、これらの質問はレビュー画面に表示されません。
ステージング ゾーンを含む Azure Data Lake Storage アカウントがあります。
ステージング ゾーンから増分データを取り込み、R スクリプトを実行してデータを変換し、変換されたデータを Azure Synapse Analytics のデータ ウェアハウスに挿入する毎日のプロセスを設計する必要があります。
解決策: Azure Data Factory スケジュール トリガーを使用して、マッピング データ フローを実行するパイプラインを実行し、データをデータ ウェアハウスに挿入します。
これは目標を満たしていますか?
DP-300 試験問題 4
Table1 という名前のテーブルを含む DB1 という名前の Microsoft SQL Server データベースがあります。
User1 という名前のユーザーのデータベース ロール メンバーシップを次の図に示します。
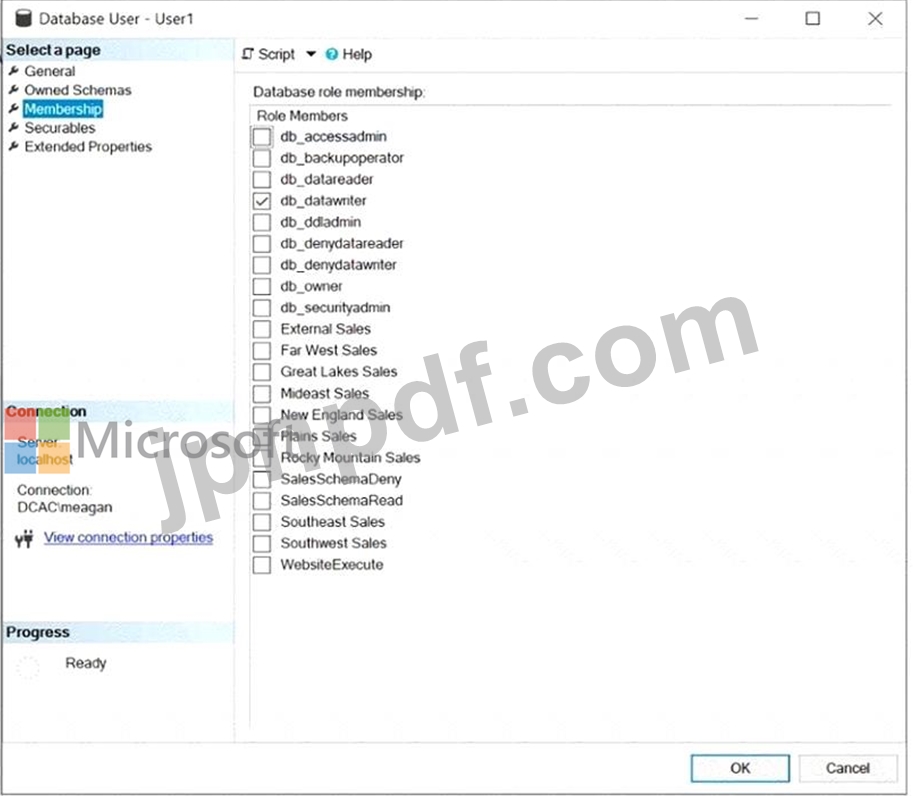
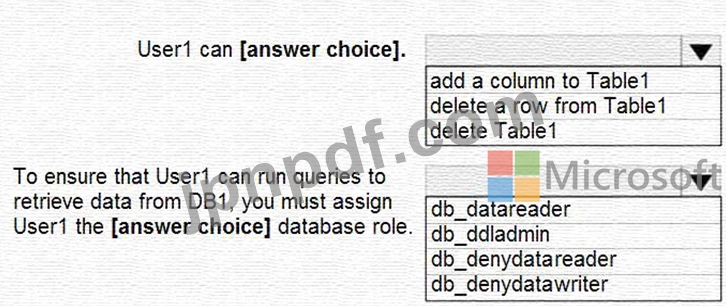
ドロップダウン メニューを使用して、グラフィックに表示されている情報に基づいて各ステートメントを完成させる回答の選択肢を選択します。
注意: 正しい選択ごとに 1 ポイントが付与されます。
User1 という名前のユーザーのデータベース ロール メンバーシップを次の図に示します。
ドロップダウン メニューを使用して、グラフィックに表示されている情報に基づいて各ステートメントを完成させる回答の選択肢を選択します。
注意: 正しい選択ごとに 1 ポイントが付与されます。


DP-300 試験問題 5
PipelineA と PipelineB という 2 つのパイプラインを持つ Azure データ ファクトリがあります。
PipelineA には、次の図に示すように 4 つのアクティビティがあります。

PipelineB には、次の図に示すように 2 つのアクティビティがあります。

両方のパイプラインとすべての失敗の種類に対して失敗したパイプライン実行メトリックを使用するデータ ファクトリのアラートを作成します。メトリックには次の設定があります。
演算子: より大きい
集計タイプ: 合計
閾値: 2
集計粒度(期間): 5分
評価頻度: 5分ごと
Data Factory の監視では、次の表に示す障害が記録されます。
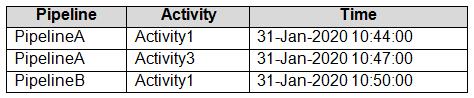
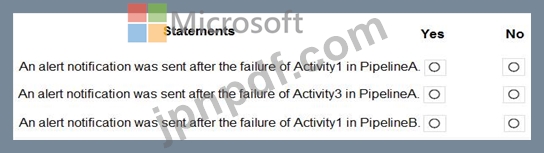
次の各文について、正しい場合は「はい」を選択してください。そうでない場合は「いいえ」を選択してください。
注意: 正しい選択ごとに 1 ポイントが付与されます。
PipelineA には、次の図に示すように 4 つのアクティビティがあります。
PipelineB には、次の図に示すように 2 つのアクティビティがあります。
両方のパイプラインとすべての失敗の種類に対して失敗したパイプライン実行メトリックを使用するデータ ファクトリのアラートを作成します。メトリックには次の設定があります。
演算子: より大きい
集計タイプ: 合計
閾値: 2
集計粒度(期間): 5分
評価頻度: 5分ごと
Data Factory の監視では、次の表に示す障害が記録されます。
次の各文について、正しい場合は「はい」を選択してください。そうでない場合は「いいえ」を選択してください。
注意: 正しい選択ごとに 1 ポイントが付与されます。
