DP-203 試験問題 56
ある企業は、Platform-as-a-Service (PaaS) を使用して新しいデータ パイプライン プロセスを作成することを計画しています。プロセスは次の要件を満たす必要があります。
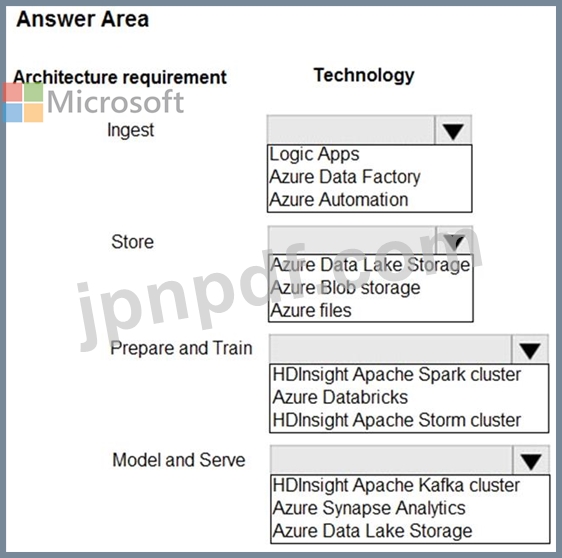
摂取:
複数のデータ ソースにアクセスします。
ワークフローを調整する機能を提供します。
SQL Server Integration Services パッケージを実行する機能を提供します。
店:
ビッグデータ ワークロード向けにストレージを最適化します。
保存データの暗号化を提供します。
サイズ制限なしで操作します。
準備とトレーニング:
探索と視覚化のための完全に管理されたインタラクティブなワークスペースを提供します。
R、SQL、Python、Scala、Java でプログラミングする機能を提供します。
Azure Active Directory を使用してシームレスなユーザー認証を提供します。
モデル&サーブ:
ネイティブの列指向ストレージを実装します。
SQL言語のサポート
構造化ストリーミングのサポートを提供します。
データ統合パイプラインを構築する必要があります。
どのテクノロジーを使用すべきでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが付与されます。
摂取:
複数のデータ ソースにアクセスします。
ワークフローを調整する機能を提供します。
SQL Server Integration Services パッケージを実行する機能を提供します。
店:
ビッグデータ ワークロード向けにストレージを最適化します。
保存データの暗号化を提供します。
サイズ制限なしで操作します。
準備とトレーニング:
探索と視覚化のための完全に管理されたインタラクティブなワークスペースを提供します。
R、SQL、Python、Scala、Java でプログラミングする機能を提供します。
Azure Active Directory を使用してシームレスなユーザー認証を提供します。
モデル&サーブ:
ネイティブの列指向ストレージを実装します。
SQL言語のサポート
構造化ストリーミングのサポートを提供します。
データ統合パイプラインを構築する必要があります。
どのテクノロジーを使用すべきでしょうか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが付与されます。

DP-203 試験問題 57
Dataflow1 という名前のデータ フロー アクティビティを含む Pipeline1 という名前の Azure Synapse Analytics パイプラインがあります。
Pipeline1 は、storage1 という名前の Azure Data Lake Storage Gen 2 アカウントからファイルを取得します。
Dataflow1 は、コア数が 128 に構成された AutoResolveIntegrationRuntime 統合ランタイムを使用します。
storage1 内のファイルのサイズに対応するために、Dataflow1 で使用されるコアの数を最適化する必要があります。
何を設定する必要がありますか? 回答するには、回答領域で適切なオプションを選択してください。

Pipeline1 は、storage1 という名前の Azure Data Lake Storage Gen 2 アカウントからファイルを取得します。
Dataflow1 は、コア数が 128 に構成された AutoResolveIntegrationRuntime 統合ランタイムを使用します。
storage1 内のファイルのサイズに対応するために、Dataflow1 で使用されるコアの数を最適化する必要があります。
何を設定する必要がありますか? 回答するには、回答領域で適切なオプションを選択してください。

DP-203 試験問題 58
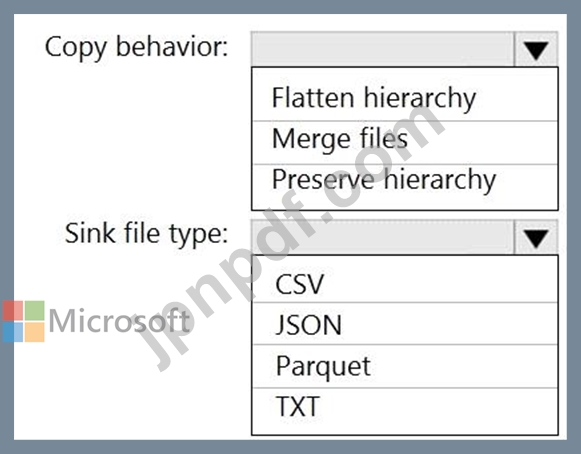
Azure Data Factory を使用して、Azure Synapse Analytics サーバーレス SQL プールによってクエリされるデータを準備します。
ファイルは最初に 10 個の小さな JSON ファイルとして Azure Data Lake Storage Gen2 アカウントに取り込まれます。各ファイルには、会社の子会社からの同じデータ属性とデータが含まれています。
次の要件を満たすように、ファイルを別のフォルダーに移動し、データを変換する必要があります。
可能な限り最速のクエリ時間を提供します。
基礎となるファイルからスキーマを自動的に推測します。
Data Factory のコピー アクティビティをどのように構成すればよいですか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが付与されます。
ファイルは最初に 10 個の小さな JSON ファイルとして Azure Data Lake Storage Gen2 アカウントに取り込まれます。各ファイルには、会社の子会社からの同じデータ属性とデータが含まれています。
次の要件を満たすように、ファイルを別のフォルダーに移動し、データを変換する必要があります。
可能な限り最速のクエリ時間を提供します。
基礎となるファイルからスキーマを自動的に推測します。
Data Factory のコピー アクティビティをどのように構成すればよいですか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが付与されます。

DP-203 試験問題 59
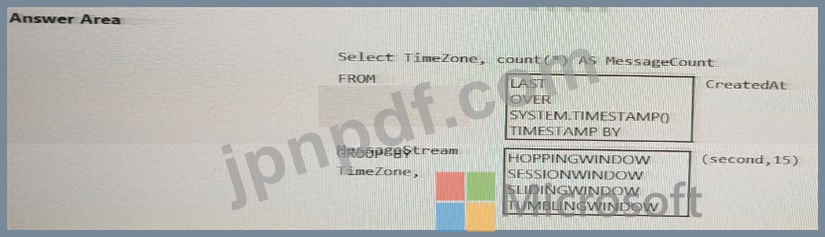
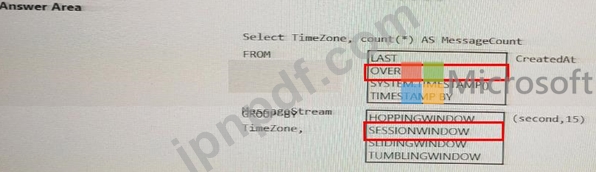
Azure イベント ハブからインスタント メッセージング データを受信する Azure Stream Analytics ソリューションを設計しています。
Stream Analytics ジョブからの出力で、タイム ゾーンごとのメッセージ数が 15 秒ごとにカウントされるようにする必要があります。
Stream Analytics クエリをどのように完了すればよいですか? 回答するには、回答領域で適切なオプションを選択します。
注意: 正しい選択ごとに 1 ポイントが付与されます。
Stream Analytics ジョブからの出力で、タイム ゾーンごとのメッセージ数が 15 秒ごとにカウントされるようにする必要があります。
Stream Analytics クエリをどのように完了すればよいですか? 回答するには、回答領域で適切なオプションを選択します。
注意: 正しい選択ごとに 1 ポイントが付与されます。
DP-203 試験問題 60
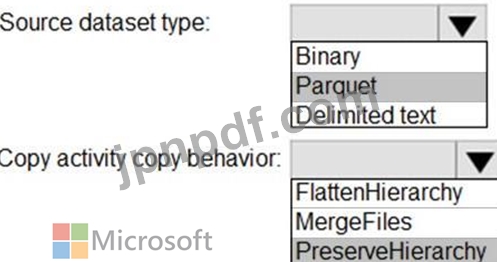
Storage1 と Storage2 という 2 つの Azure Storage アカウントがあります。各アカウントには 1 つのコンテナーが保持され、階層型名前空間が有効になっています。システムには、Apache Parquet 形式で保存されたデータを含むファイルがあります。
Data Factory のコピー アクティビティを使用して、フォルダーとファイルを Storage1 から Storage2 にコピーする必要があります。ソリューションは、次の要件を満たしている必要があります。
変換を実行する必要はありません。
元のフォルダ構造を保持する必要があります。
コピー アクティビティの実行に必要な時間を最小限に抑えます。
コピー アクティビティをどのように構成すればよいですか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが付与されます。

Data Factory のコピー アクティビティを使用して、フォルダーとファイルを Storage1 から Storage2 にコピーする必要があります。ソリューションは、次の要件を満たしている必要があります。
変換を実行する必要はありません。
元のフォルダ構造を保持する必要があります。
コピー アクティビティの実行に必要な時間を最小限に抑えます。
コピー アクティビティをどのように構成すればよいですか? 回答するには、回答領域で適切なオプションを選択してください。
注意: 正しい選択ごとに 1 ポイントが付与されます。