
DP-203 試験問題 76
注:この質問は、同じシナリオを提示する一連の質問の一部です。シリーズの各質問には、述べられた目標を達成する可能性のある独自の解決策が含まれています。一部の質問セットには複数の正しい解決策がある場合がありますが、他の質問セットには正しい解決策がない場合があります。
このセクションの質問に回答した後は、その質問に戻ることはできません。その結果、これらの質問はレビュー画面に表示されません。
階層構造のAzureDatabricksワークスペースを作成する予定です。ワークスペースには、次の3つのワークロードが含まれます。
PythonとSQLを使用するデータエンジニアのワークロード。
Python、Scala、およびSOLを使用するノートブックを実行するジョブのワークロード。
データサイエンティストがScalaとRでアドホック分析を実行するために使用するワークロード。
会社のエンタープライズアーキテクチャチームは、Databricks環境の次の標準を特定します。
データエンジニアはクラスターを共有する必要があります。
ジョブクラスターは、データサイエンティストとデータエンジニアがクラスターに展開するためのパッケージ化されたノートブックを提供する要求プロセスを使用して管理されます。
すべてのデータサイエンティストには、120分間操作がないと自動的に終了する独自のクラスターを割り当てる必要があります。現在、3人のデータサイエンティストがいます。
ワークロード用のDatabricksクラスターを作成する必要があります。
解決策:データサイエンティストごとに標準クラスター、データエンジニア用に標準クラスター、ジョブ用に高同時実行クラスターを作成します。
これは目標を達成していますか?
このセクションの質問に回答した後は、その質問に戻ることはできません。その結果、これらの質問はレビュー画面に表示されません。
階層構造のAzureDatabricksワークスペースを作成する予定です。ワークスペースには、次の3つのワークロードが含まれます。
PythonとSQLを使用するデータエンジニアのワークロード。
Python、Scala、およびSOLを使用するノートブックを実行するジョブのワークロード。
データサイエンティストがScalaとRでアドホック分析を実行するために使用するワークロード。
会社のエンタープライズアーキテクチャチームは、Databricks環境の次の標準を特定します。
データエンジニアはクラスターを共有する必要があります。
ジョブクラスターは、データサイエンティストとデータエンジニアがクラスターに展開するためのパッケージ化されたノートブックを提供する要求プロセスを使用して管理されます。
すべてのデータサイエンティストには、120分間操作がないと自動的に終了する独自のクラスターを割り当てる必要があります。現在、3人のデータサイエンティストがいます。
ワークロード用のDatabricksクラスターを作成する必要があります。
解決策:データサイエンティストごとに標準クラスター、データエンジニア用に標準クラスター、ジョブ用に高同時実行クラスターを作成します。
これは目標を達成していますか?
DP-203 試験問題 77
Azure Databricksを使用して、DBTBL1という名前のデータセットを開発します。
DBTBL1には、次の列が含まれています。
SensorTypeID
GeographyRegionID
年
月
日
時間
分
温度
風速
他の
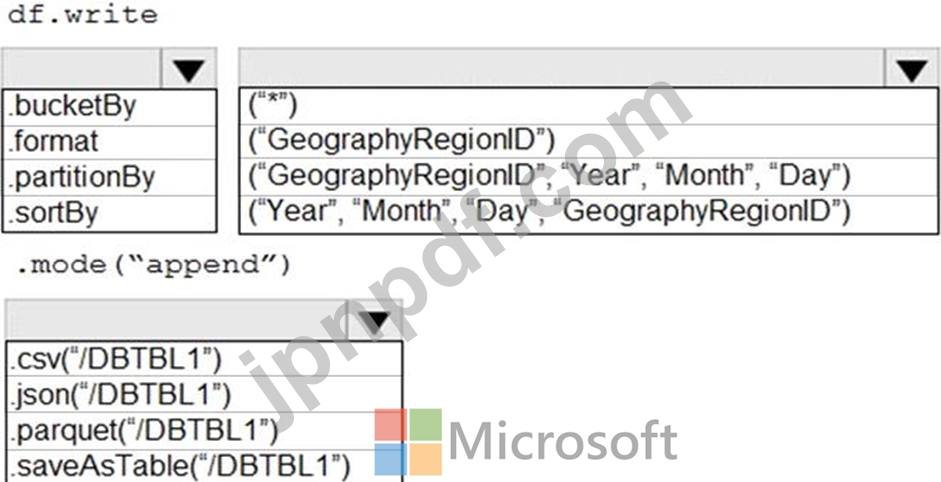
GeographyRegionIDごとに異なる毎日の増分ロードパイプラインをサポートするために、データを保存する必要があります。このソリューションでは、ストレージコストを最小限に抑える必要があります。
コードをどのように完成させる必要がありますか?回答するには、回答エリアで適切なオプションを選択してください。
注:正しい選択はそれぞれ1ポイントの価値があります。
DBTBL1には、次の列が含まれています。
SensorTypeID
GeographyRegionID
年
月
日
時間
分
温度
風速
他の
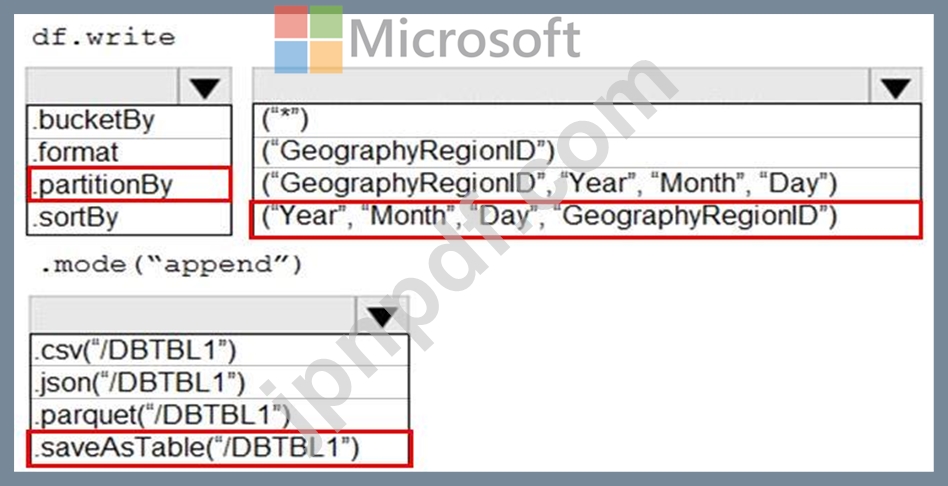
GeographyRegionIDごとに異なる毎日の増分ロードパイプラインをサポートするために、データを保存する必要があります。このソリューションでは、ストレージコストを最小限に抑える必要があります。
コードをどのように完成させる必要がありますか?回答するには、回答エリアで適切なオプションを選択してください。
注:正しい選択はそれぞれ1ポイントの価値があります。
DP-203 試験問題 78
Twitterフィードデータを専用のSQLプールで分析できることを確認する必要があります。ソリューションは、顧客の感情分析の要件を満たす必要があります。
順番に実行する必要がある3つのTransaction-SQLDDLコマンドはどれですか。応答するには、適切なコマンドをコマンドのリストから応答領域に移動し、正しい順序に並べます。
注:回答の選択肢の複数の順序が正しいです。選択した正しい注文のいずれかに対してクレジットを受け取ります。

順番に実行する必要がある3つのTransaction-SQLDDLコマンドはどれですか。応答するには、適切なコマンドをコマンドのリストから応答領域に移動し、正しい順序に並べます。
注:回答の選択肢の複数の順序が正しいです。選択した正しい注文のいずれかに対してクレジットを受け取ります。

DP-203 試験問題 79
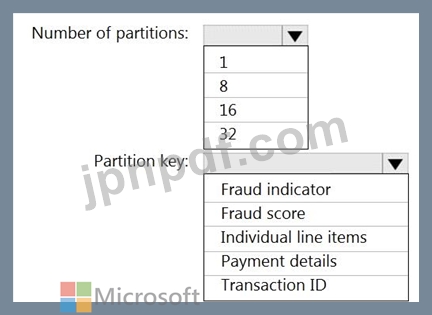
16個のパーティションを持つretailhubという名前のAzureイベントハブがあります。トランザクションはretailhubに転記されます。各トランザクションには、トランザクションID、個々のラインアイテム、および支払いの詳細が含まれます。トランザクションIDはパーティションキーとして使用されます。
小売店での不正の可能性のあるトランザクションを特定するために、AzureStreamAnalyticsジョブを設計しています。ジョブはretailhubを入力として使用します。ジョブは、トランザクションID、個々のラインアイテム、支払いの詳細、不正スコア、および不正インジケーターを出力します。
出力をfraudhubという名前のAzureイベントハブに送信することを計画しています。
不正検出ソリューションが高度にスケーラブルであり、トランザクションを可能な限り迅速に処理することを確認する必要があります。
Stream Analyticsジョブの出力をどのように構成する必要がありますか?回答するには、回答エリアで適切なオプションを選択してください。
注:正しい選択はそれぞれ1ポイントの価値があります。
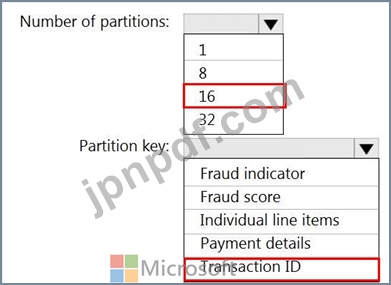
小売店での不正の可能性のあるトランザクションを特定するために、AzureStreamAnalyticsジョブを設計しています。ジョブはretailhubを入力として使用します。ジョブは、トランザクションID、個々のラインアイテム、支払いの詳細、不正スコア、および不正インジケーターを出力します。
出力をfraudhubという名前のAzureイベントハブに送信することを計画しています。
不正検出ソリューションが高度にスケーラブルであり、トランザクションを可能な限り迅速に処理することを確認する必要があります。
Stream Analyticsジョブの出力をどのように構成する必要がありますか?回答するには、回答エリアで適切なオプションを選択してください。
注:正しい選択はそれぞれ1ポイントの価値があります。
DP-203 試験問題 80
Table1という名前のテーブルを含むAzureSynapseAnalytics専用のSQLプールがあります。
container1という名前のAzureDataLakeStorageGen2コンテナーに取り込まれてロードされるファイルがあります。
ファイルからTable1にデータを挿入し、container1という名前のData LakeStorageGen2コンテナを紺碧にする予定です。
ファイルからTable1にデータを挿入し、データを変換することを計画しています。ファイル内のデータの各行は、Table1のサービングレイヤーに1つの行を生成します。
ソースデータファイルがcontainer1にロードされるときに、DateTimeが追加の列としてTable1に格納されていることを確認する必要があります。
解決策:Azure Synapse Analyticsパイプラインでは、派生列変換を含むデータフローを使用します。
container1という名前のAzureDataLakeStorageGen2コンテナーに取り込まれてロードされるファイルがあります。
ファイルからTable1にデータを挿入し、container1という名前のData LakeStorageGen2コンテナを紺碧にする予定です。
ファイルからTable1にデータを挿入し、データを変換することを計画しています。ファイル内のデータの各行は、Table1のサービングレイヤーに1つの行を生成します。
ソースデータファイルがcontainer1にロードされるときに、DateTimeが追加の列としてTable1に格納されていることを確認する必要があります。
解決策:Azure Synapse Analyticsパイプラインでは、派生列変換を含むデータフローを使用します。