
DP-100 試験問題 106
自動機械学習を使用して回帰モデルをトレーニングすることを計画しています。値が欠落している特徴と、明確な値がほとんどないカテゴリの特徴を含むデータがあります。
トレーニングタスクの一部として、欠測値を自動的に代入し、カテゴリ機能をエンコードするように自動機械学習を構成する必要があります。
AutoMLConfigクラスでどのパラメーターと値のペアを使用する必要がありますか?
トレーニングタスクの一部として、欠測値を自動的に代入し、カテゴリ機能をエンコードするように自動機械学習を構成する必要があります。
AutoMLConfigクラスでどのパラメーターと値のペアを使用する必要がありますか?



DP-100 試験問題 107
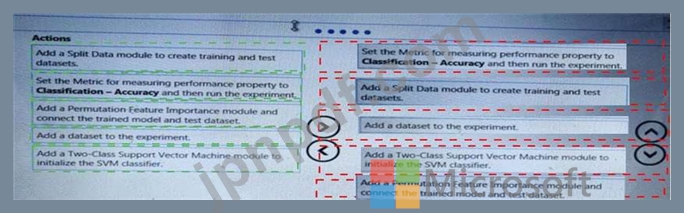
150を超える機能を含むデータセットがあります。データセットを使用して、サポートベクターマシン(SVM)バイナリ分類器をトレーニングします。
データセットの特徴重要度スコアのセットを計算するには、Azure MachineLearningStudioの順列特徴重要度モジュールを使用する必要があります。
アクションを実行する順序はどれですか。回答するには、アクションのリストから回答領域に移動し、正しい順序で並べます。
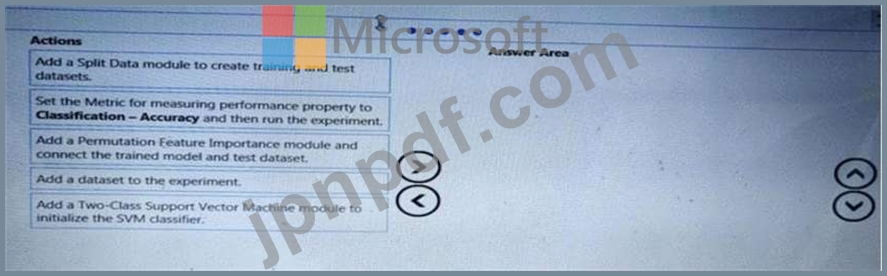
データセットの特徴重要度スコアのセットを計算するには、Azure MachineLearningStudioの順列特徴重要度モジュールを使用する必要があります。
アクションを実行する順序はどれですか。回答するには、アクションのリストから回答領域に移動し、正しい順序で並べます。
DP-100 試験問題 108
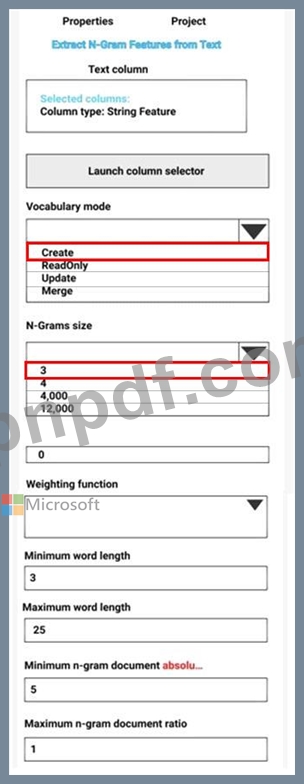
短い文の形式で書かれた12,000件の顧客レビューを含むCSVファイルを使用して感情分析を実行しています。CSVファイルをAzureMachineLearning Studioに追加し、実験の開始点データセットとして構成します。[テキストからN-Gram機能を抽出]モジュールを実験に追加して、データセットのカスタマーレビュー列からキーフレーズを抽出します。
カスタマーレビューテキストから新しいn-gram辞書を作成し、最大n-gramサイズをトリグラムに設定する必要があります。
何を選ぶべきですか?回答するには、回答エリアで適切なオプションを選択してください。
注:正しい選択はそれぞれ1ポイントの価値があります。

カスタマーレビューテキストから新しいn-gram辞書を作成し、最大n-gramサイズをトリグラムに設定する必要があります。
何を選ぶべきですか?回答するには、回答エリアで適切なオプションを選択してください。
注:正しい選択はそれぞれ1ポイントの価値があります。
DP-100 試験問題 109
AzureMachineLearningワークスペースを作成します。
次の要件を満たすDataScientistという名前のカスタムロールを作成する必要があります。
*ロールメンバーはワークスペースを削除できないようにする必要があります。
*ロールメンバーは、ワークスペースでコンピューティングリソースを作成、更新、または削除できないようにする必要があります。
*ロールメンバーは、ワークスペースに新しいユーザーを追加できないようにする必要があります。
AzureMachineLearningワークスペースでDataScientistロールのJSONファイルを作成する必要があります。
カスタムロールは、IT運用チームによって指定された制限を適用する必要があります。
どのJSONコードセグメントを使用する必要がありますか?
A)

B)

C)
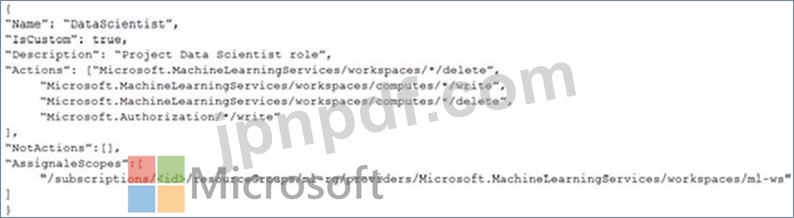
D)

次の要件を満たすDataScientistという名前のカスタムロールを作成する必要があります。
*ロールメンバーはワークスペースを削除できないようにする必要があります。
*ロールメンバーは、ワークスペースでコンピューティングリソースを作成、更新、または削除できないようにする必要があります。
*ロールメンバーは、ワークスペースに新しいユーザーを追加できないようにする必要があります。
AzureMachineLearningワークスペースでDataScientistロールのJSONファイルを作成する必要があります。
カスタムロールは、IT運用チームによって指定された制限を適用する必要があります。
どのJSONコードセグメントを使用する必要がありますか?
A)
B)
C)
D)
DP-100 試験問題 110
注:この質問は、同じシナリオを提示する一連の質問の一部です。シリーズの各質問には、述べられた目標を達成する可能性のある独自の解決策が含まれています。一部の質問セットには複数の正しい解決策がある場合がありますが、他の質問セットには正しい解決策がない場合があります。
このセクションの質問に回答した後は、その質問に戻ることはできません。その結果、これらの質問はレビュー画面に表示されません。
Azure MachineLearningStudioで新しい実験を作成しています。
1つのクラスには、トレーニングセット内の他のクラスよりもはるかに少ない数の観測値があります。
クラスの不均衡を補うために、適切なデータサンプリング戦略を選択する必要があります。
解決策:ScaleandReduceサンプリングモードを使用します。
ソリューションは目標を達成していますか?
このセクションの質問に回答した後は、その質問に戻ることはできません。その結果、これらの質問はレビュー画面に表示されません。
Azure MachineLearningStudioで新しい実験を作成しています。
1つのクラスには、トレーニングセット内の他のクラスよりもはるかに少ない数の観測値があります。
クラスの不均衡を補うために、適切なデータサンプリング戦略を選択する必要があります。
解決策:ScaleandReduceサンプリングモードを使用します。
ソリューションは目標を達成していますか?