
Databricks-Generative-AI-Engineer-Associate 試験問題 1
ジェネレーティブ AI エンジニアは、新たにスコープ設定されたプロジェクトに最適な従業員チーム メンバーを提案するジェネレーティブ AI システムを構築しています。チーム メンバーは、非常に大規模なチームから選択されます。マッチングは、プロジェクトの日付の空き状況と、従業員プロファイルがプロジェクト スコープにどの程度適合しているかに基づいて行われます。従業員プロファイルとプロジェクト スコープはどちらも非構造化テキストです。
ジェネレーティブ AI エンジニアはシステムをどのように設計すべきでしょうか?
ジェネレーティブ AI エンジニアはシステムをどのように設計すべきでしょうか?
Databricks-Generative-AI-Engineer-Associate 試験問題 2
Generative AI エンジニアが以下のコードを使用して LangChain で簡単なプロンプト テンプレートをテストしていますが、エラーが発生しています。
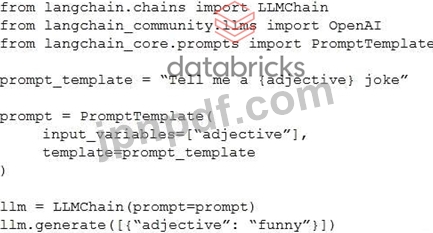
API キーが適切に定義されていると仮定すると、Generative AI エンジニアはチェーンを修正するためにどのような変更を加える必要がありますか?
API キーが適切に定義されていると仮定すると、Generative AI エンジニアはチェーンを修正するためにどのような変更を加える必要がありますか?
Databricks-Generative-AI-Engineer-Associate 試験問題 3
ジェネレーティブ AI エンジニアは、社内のナレッジ ベースを活用して、社内の小規模な専門家グループが特定の質問に答えるのに役立つ RAG アプリケーションの開発を任されています。エンジニアは、回答に可能な限り最高の品質を求めており、ユーザー グループが小規模で、最適な回答を待つ用意があることを考えると、レイテンシもスループットも大きな問題ではありません。トピックは機密性が高く、データは機密性が高いため、規制要件により、情報を第三者に送信することは許可されていません。
この状況で、ジェネレーティブ AI エンジニアのすべてのニーズを満たすモデルはどれですか?
この状況で、ジェネレーティブ AI エンジニアのすべてのニーズを満たすモデルはどれですか?
Databricks-Generative-AI-Engineer-Associate 試験問題 4
RAG パイプラインで応答を生成する LLM を GPT-4 から、会社がセルフホストするコンテキスト長の短いモデルに変更した後、Generative AI エンジニアは次のエラーを受け取ります。

生成 AI エンジニアは、応答生成モデルを変更せずにどのような 2 つのソリューションを実装する必要がありますか? (2 つ選択してください。)
生成 AI エンジニアは、応答生成モデルを変更せずにどのような 2 つのソリューションを実装する必要がありますか? (2 つ選択してください。)
Databricks-Generative-AI-Engineer-Associate 試験問題 5
ジェネレーティブ AI エンジニアが非構造化ドキュメントを正常に取り込み、ドキュメント セクションごとにチャンク化しました。チャンクを Vector Search インデックスに保存したいと考えています。データフレームの現在の形式には、(i) 元のドキュメント ファイル名、(ii) 各ドキュメントのテキスト チャンクの配列という 2 つの列があります。
このデータフレームを保存する最もパフォーマンスの高い方法は何ですか?
このデータフレームを保存する最もパフォーマンスの高い方法は何ですか?